tl;dr; It's a web app where you search and find the podcasts you listen to. It then gives you a break down how much time that requires to keep up, per day, per week and per month. Podcasttime.io

First I wrote some scripts to scrape various sources of podcasts. This is basically a RSS feed URL from which you can fetch the name and an image. And with some cron jobs you can download and parse each podcast feed and build up an index of how many episodes they have and how long each episode is. Together with each episodes "publish date" you can easily figure out an average of how much content each podcast puts out over time.
Suppose you listen to JavaScript Air, Talk Python To Me and Google Cloud Platform Podcast for example, that means you need to listen to podcasts for about 8 minutes per day to keep up.
The Back End
The technology is exciting. The backend is a Django 1.10 server. It manages a PostgreSQL database of all the podcasts, episodes, cron jobs etc. Through Django ORM signals is packages up each podcast with its metadata and stores it in an Elasticsearch database. All the communication between Django and ElasticSearch is done with Elasticsearch DSL.
Also, all the downloading and parsing of feeds is done as background tasks in Celery. This got really interesting/challenging because sooo many podcasts are poorly marked up and many a times the only way to find out how long an episode is is to use ffmpeg to probe it and that takes time.
Another biggish challenge is that fact that often things simply don't work because of networks being what they are, unreliable. So you have to re-attempt network calls without accidentally getting caught in infinite loops of accidentally putting a bad/broken RSS feed back into the background queue again and again and again.
The Front End
Actually, the first prototype of this app was written with Django as the front end plus some jQuery to tie things together. On a plane ride, and as an excuse to learn it, I re-wrote the whole thing in React with Redux. To be honest, I never really enjoyed that and it felt like everything was hard and I had to do more jumping-around-files than actual coding. In particular, Redux is nice but when you have a lot of AJAX both inside components and upon mounting it gets quite messy in my humble opinion.
So, on another plane ride (to Hawaii, so I had more time) I re-wrote it from scratch but this time using three beautiful pieces of front end technology: create-react-app, Mobx and mobx-router. Suddenly it became fun again. Mobx (or Redux or something "fluxy") is necessary if you want fancy pushState URLs AND a central (aka global) state management.
To be perfectly honest, I never actually tried combining Mobx with something like react-router or if it's even possible. But with mobx-router it's quite neat. You write a "views route map" (see example) where you can kick off AJAX before entering (and leaving) routes. Then you use that to populate a global store and now all components can be almost entirely about simply rendering the store. There is some AJAX within the mounted components (e.g. the search and autocomplete).
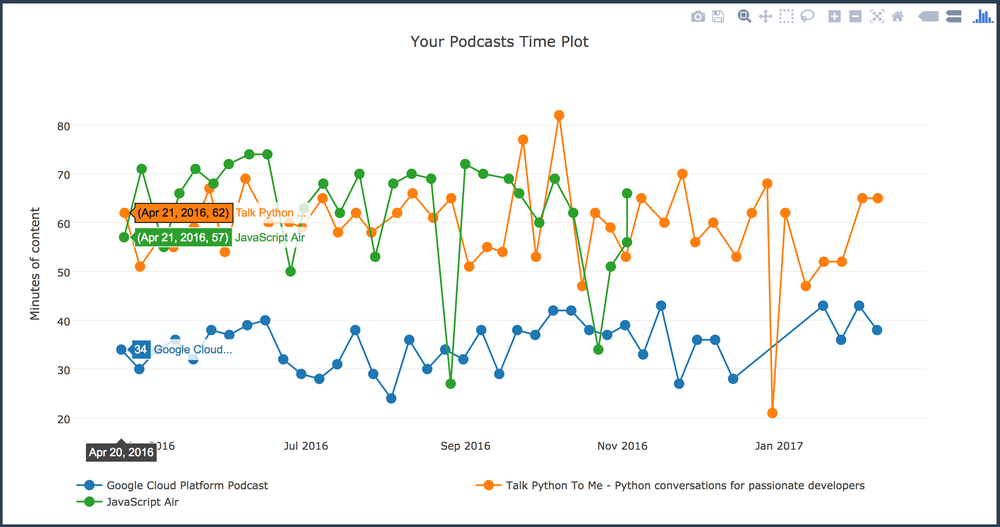
On the home page, there's a chart that rather unscientifically plots episode durations over time as a line chart. I'm trying a library called Plotly which is actually a online app for building charts but they offer a free JavaScript library too for generating graphs. Not entirely sure how I feel about it yet but apart from looking a big crowded on mobile, it's working really well.
A Killer Feature
This is a pattern I've wanted to build but never managed to get right. The way to get data about a podcast (and its episodes) is to do an Elasticsearch search. From the homepage you basically call /find?q=Planet%20money when you search. That gives you almost all the information you need. So you store that in the global store. Then, if the user clicks on that particular podcast to go to its "perma page" you can simply load that podcast's individual route and you don't need to do something like /find?id=727 because you already have everything you need. If the user then opens that page in a new tab or reloads you now have to fetch just the one podcast, so you simply call /find?id=727. In other words, subsequent page loads load instantly! (Basically, it updates the store's podcast object upon clicking any of the podcasts iterated over from the listing. Code here)
And to top that - and this is where a good router shines - if you make a search or something, click something and click back since you have a global store of state, you can simply reuse that without needing another AJAX query.
The State of the Future
First of all, this is a fun little side project and it's probably buggy. My goal is not to make money on it but to build up a graph. Every time someone uses the site and finds the podcasts they listen to that slowly builds up connections. If you listen to "The Economist", "Planet Money" and "Freakonomics", that tie those together loosely. It's hard to programmatically know that those three podcasts are "related" but they are by "peoples' taste".
The ultimate goal of this is; now I can recommend other podcasts based on a given set. It's a little bit like LastFM used to work. Using Audioscrobbler LastFM was able to build up a graph based on what people preferred to listen to and using that network of knowledge they can recommend things you have not listened to but probably would appreciate.
At the moment, there's a simple Picks listing of "lists" (aka "picks") that people have chosen. With enough time and traffic I'll try to use Elasticsearch's X-Pack Graph capabilities to develop a search engine based on this.
At the time of writing, I've indexed 4,669 podcasts, spanning 611,025 episodes which equates to 549,722 hours of podcast content.
The Code
The front end code is available on github.com/peterbe/podcasttime2 and is relatively neat and tidy. The most interesting piece is probably the views/index.js which is the "controller" of things. That's where it decides which component to render, does the AJAX queries and manages the global store.
The back end code is a bit messier. It's done as an "app" as part of this very blog. The way the Elasticsearch indexing is configured is here and the hotch potch code for scraping and parsing RSS feeds is here.
Please try it out and show me your selection. You can drop feedback here.
Comments
Nice tool, thank you for it!
One Question: Each time I add a podcast to the list "minutes per day" gets smaller? I'd expect that I need more time if I listen to more podcasts.
Where is my mistake?
Oh no! Sounds like a bug. Can you share, with me, which podcasts you added?
Thanks again!
I emailed you an update. It should be better now.