tl;dr; In other words, you can now have multiple servers with crontabber, all talking to a central PostgreSQL for its state, and not have to worry about jobs being started more than exactly once. This will be super useful if your crontabber apps are such that they kick of stored procedures that would freak out if run more than once with the same parameters.
crontabber is an advanced Python program to run cron-like applications in a predictable way. Every app is a Python class with a run method. Example here. Until version 0.18 you had to do locking outside but now the locking has been "internalized". Meaning, if you open two terminals and run python crontabber.py --admin.conf=myconfig.ini in both you don't have to worry about it starting the same apps in parallel.
General, business logic locking
Every app has a state. It's stored in PostgreSQL. It looks like this:
# \d crontabber
Table "public.crontabber"
Column | Type | Modifiers
--------------+--------------------------+-----------
app_name | text | not null
next_run | timestamp with time zone |
first_run | timestamp with time zone |
last_run | timestamp with time zone |
last_success | timestamp with time zone |
error_count | integer | default 0
depends_on | text[] |
last_error | json |
ongoing | timestamp with time zone |
Indexes:
"crontabber_unique_app_name_idx" UNIQUE, btree (app_name)
The last column, ongoing used to be just for the "curiosity". For example, in Socorro we used that to display a flashing message about which jobs are ongoing right now.
As of version 0.18, this ongoing column is actually used to NOT run apps again. Basically, when started, crontabber figures out which app to run next (assuming it's time to run it) and now the first thing it does is look up if it's ongoing already, and if it is the whole crontabber application exits with an error code of 3.
Sub-second locking
What might happen is that two separate servers which almost perfectly synchronoized clocks might have cron run crontabber at the "exact" same time. Or rather, only a few milliseconds apart. But the database is central so what might happen is that two distinct PostgreSQL connection tries to send a... UPDATE crontabber SET ongoing=now() WHERE app_name='some-app-name' at the very same time.
So how is this solved? The answer is row-level locking. The magic sauce is here. You make a select, by app_name with a suffix of FOR UPDATE WAIT. Imagine two distinct PostgreSQL connections sending this:
BEGIN;
SELECT ongoing FROM crontabber WHERE app_name = 'my-app-name'
FOR UPDATE NOWAIT;
-- do some other stuff in Python
UPDATE crontabber SET ongoing = now() WHERE app_name = 'my-app-name';
COMMIT;
One of them will succeed the other will raise an error. Now all you need to do is catch that raised error, check that it's a row-level locking error and not some other general error. Instead of worrying about the raised error you just accept it and exit the program early.
This screenshot of a test.sql script demonstrates this:
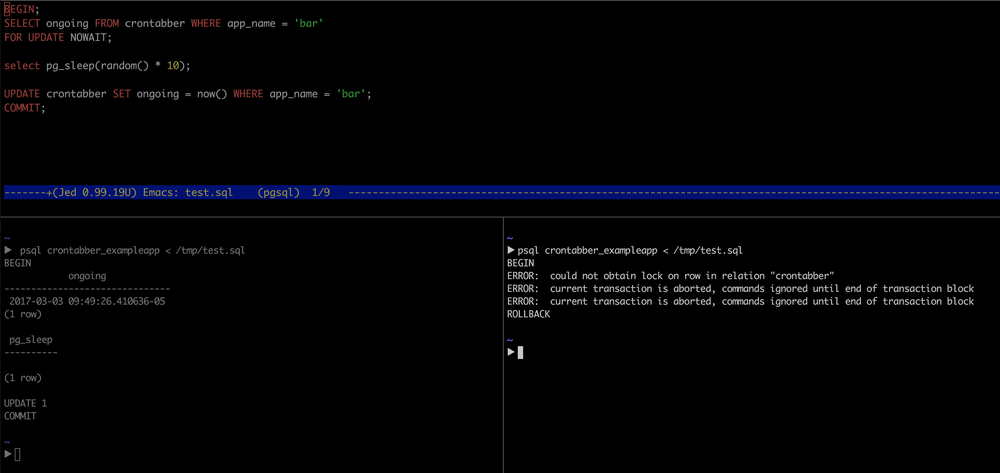
Two terminals lined up and I start one and quickly switch and start the other one
Another way to demonstrate this is to use psycopg2 in a little script:
import threading
import psycopg2
def updater():
connection = psycopg2.connect('dbname=crontabber_exampleapp')
cursor = connection.cursor()
cursor.execute("""
SELECT ongoing FROM crontabber WHERE app_name = 'bar'
FOR UPDATE NOWAIT
""")
cursor.execute("""
UPDATE crontabber SET ongoing = now() WHERE app_name = 'bar'
""")
print("JOB CAN START!")
connection.commit()
# Use threads to simulate starting two connections virtually
# simultaneously.
threads = [
threading.Thread(target=updater),
threading.Thread(target=updater),
]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
The output of this is:
▶ python /tmp/test.py JOB CAN START! Exception in thread Thread-1: Traceback (most recent call last): ... OperationalError: could not obtain lock on row in relation "crontabber"
With threads, you never know exactly which one will work and which one will not. In this case it was Thread-1 that sent its SQL a couple of nanoseconds too late.
In conclusion...
As of version 0.18 of crontabber, all locking is now dealt with inside crontabber. You still kick off crontabber from cron or crontab but if your cron does kick it off whilst it's still in the midst of running a job, it will simply exit with an error code of 2 or 3.
In other words, you can now have multiple servers with crontabber, all talking to a central PostgreSQL for its state, and not have to worry about jobs being started more than exactly once. This will be super useful if your crontabber apps are such that they kick of stored procedures that would freak out if run more than once with the same parameters.