Now that Autocompeter.com is launched I can publish some preliminary benchmarks of "real" usage. It's all on my MacBook Pro on a local network with a local Redis but it's quite telling that it's pretty fast.
What I did was I started with a completely empty Redis database then I did the following things:
First of all, I bulk load in 1035 "documents" (110Kb of data). This takes about 0.44 seconds consistently!
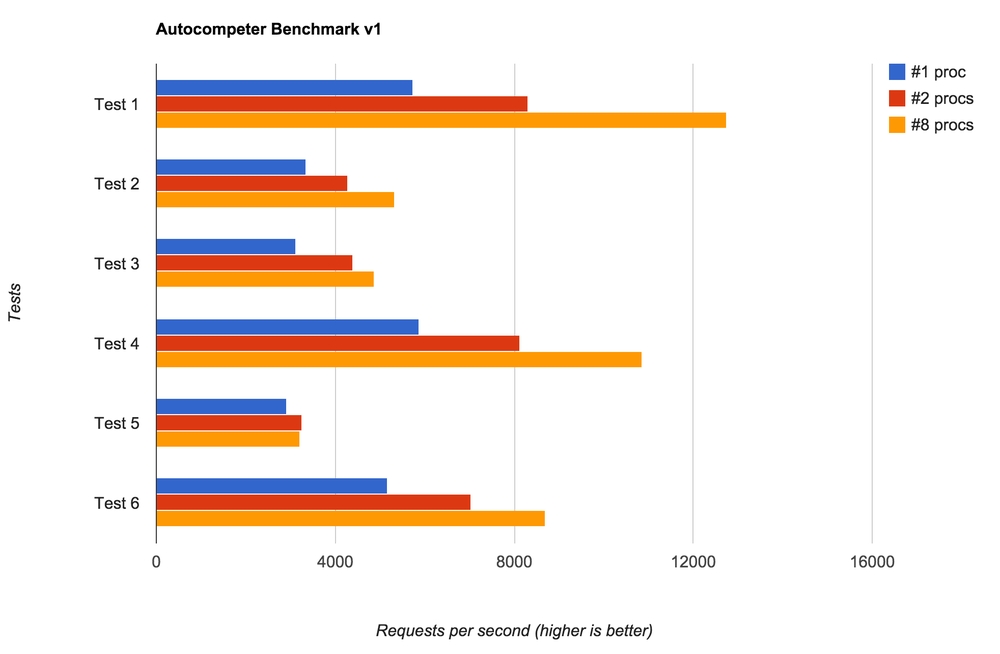
- GET on the home page (not part of the API and thus quite unimportant in terms of performance)
- GET on a search with a single character ("p") expecting 10 results (e.g.
/v1?d=mydomain&q=p) - GET on a search with a full word ("python") expecting 10 results
- GET on a search with a full word that isn't in the index ("xxxxxxxx") expecting 0 results
- GET on a search with two words ("python", "te") expecting 4 results
- GET on a search with two words that aren't in the index ("xxxxxxx", "yyyyyy") expecting 0 results
In each benchmark I use wrk with 10 connections, lasting 5 seconds, using 5 threads.
And for each round I try with 1 processor, 2 processors and 8 processors (my laptop's max according to runtime.NumCPU()).
I ran it a bunch of times and recorded the last results for each number of processors.
The results are as follows:
Notes
- Every search incurs a write in the form of incrementing a counter.
- Searching on more than one word causes an ZINTERSTORE.
- The home page does a bit more now since this benchmark was made. In particular looking for a secure cookie.
- Perhaps interally Redis could get faster if you run the benchmarks repeatedly after the bulk load so it's internals could "warm up".
- I used a pool of 100 Redis connections.
- I honestly don't know if 10 connections, 5 seconds, 5 threads is an ideal test :)
Basically, this is a benchmark of Redis more so than Go but it's quite telling that running it in multiple processors does help.
If you're curious, the benchmark code is here and I'm sure there's things one can do to speed it up even more. It's just interesting that it's so freakin' fast out of the box!
In particular I'm very pleased with the fact that it takes less than half a second to bulk load in over 1,000 documents.