This web app I'm working on gets a blob of bytes from a HTTP POST. The nature of the blob is a 100MB to 1,100MB blob of a zip file. What my app currently does is that it takes this byte buffer, uses Python's built in zipfile to extract all its content to a temporary directory. A second function then loops over the files within this extracted tree and processes each file in multiple threads with concurrent.futures.ThreadPoolExecutor. Here's the core function itself:
@metrics.timer_decorator('upload_dump_and_extract')
def dump_and_extract(root_dir, file_buffer):
zf = zipfile.ZipFile(file_buffer)
zf.extractall(root_dir)
So far so good.
Speed Speed Speed
I quickly noticed that this is amounting to quite a lot of time spent doing the unzip and the writing to disk. What to do????
At first I thought I'd shell out to good old unzip. E.g. unzip -d /tmp/tempdirextract /tmp/input.zip but that has two flaws:
1) I'd first have to dump the blob of bytes to disk and do the overhead of shelling out (i.e. Python subprocess)
2) It's actually not faster. Did some experimenting and got the same results at Alex Martelli in this Stackoverflow post
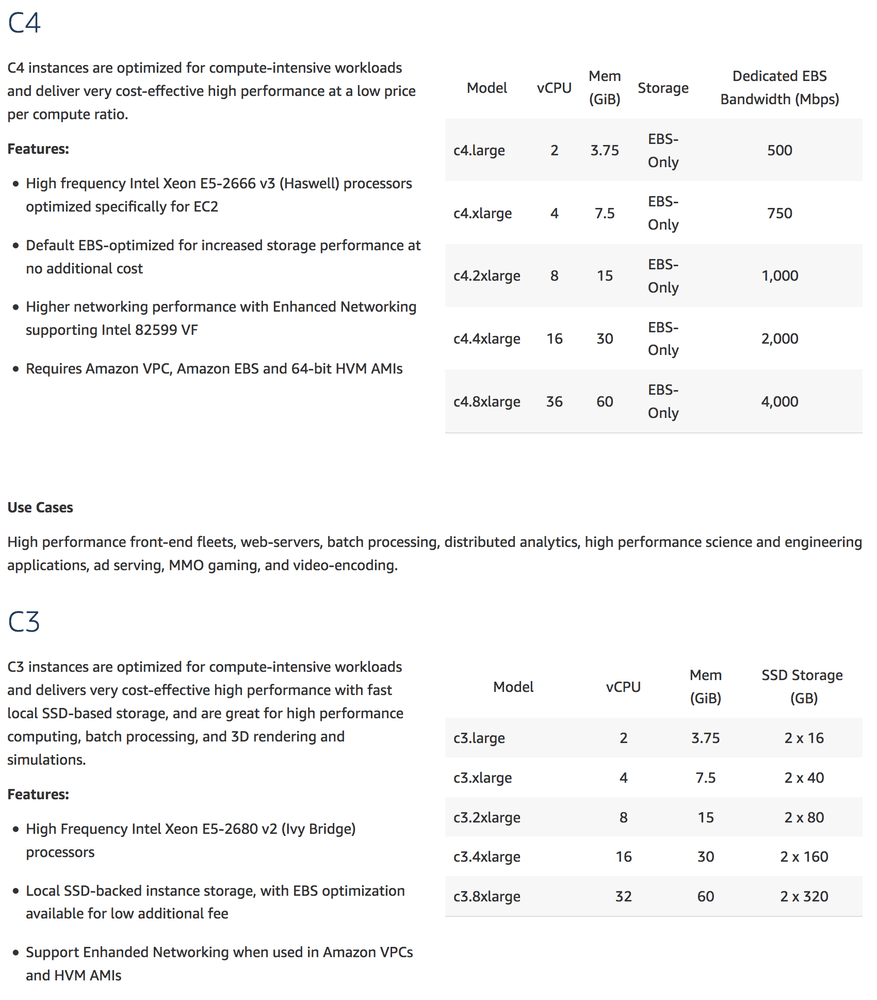
What about disk speed? Yeah, this is likely to be a part of the total time. The servers that run the symbols.mozilla.org service runs on AWS EC2 c4.large. This only has EBS (Elastic Block Storage). However, AWS EC2 c3.large looks interesting since it's using SSD disks. That's probably a lot faster. Right?
Note! For context, the kind of .zip files I'm dealing with contain many small files and often 1-2 really large ones.
EC2s Benchmarking
I create two EC2 nodes to experiment on. One c3.large and one c4.large. Both running Ubuntu 16.04.
Next, I have this little benchmarking script which loops over a directory full of .zip files between 200MB-600MB large. Roughly 10 of them. It then loads each one, one at a time, into memory and calls the dump_and_extract. Let's run it on each EC2 instance:
On c4.large
c4.large$ python3 fastest-dumper.py /tmp/massive-symbol-zips 138.2MB/s 291.1MB 2.107s 146.8MB/s 314.5MB 2.142s 144.8MB/s 288.2MB 1.990s 84.5MB/s 532.4MB 6.302s 146.6MB/s 314.2MB 2.144s 136.5MB/s 270.7MB 1.984s 85.9MB/s 518.9MB 6.041s 145.2MB/s 306.8MB 2.113s 127.8MB/s 138.7MB 1.085s 107.3MB/s 454.8MB 4.239s 141.6MB/s 251.2MB 1.774s Average speed: 127.7MB/s Median speed: 138.2MB/s Average files created: 165 Average directories created: 129
On c3.large
c3.large$ python3 fastest-dumper.py -t /mnt/extracthere /tmp/massive-symbol-zips 105.4MB/s 290.9MB 2.761s 98.1MB/s 518.5MB 5.287s 108.1MB/s 251.2MB 2.324s 112.5MB/s 294.3MB 2.615s 113.7MB/s 314.5MB 2.767s 106.3MB/s 291.5MB 2.742s 104.8MB/s 291.1MB 2.778s 114.6MB/s 248.3MB 2.166s 114.2MB/s 248.2MB 2.173s 105.6MB/s 298.1MB 2.823s 106.2MB/s 297.6MB 2.801s 98.6MB/s 521.4MB 5.289s Average speed: 107.3MB/s Median speed: 106.3MB/s Average files created: 165 Average directories created: 127
What the heck!? The SSD based instance is 23% slower!
I ran it a bunch of times and the average and median numbers are steady. c4.large is faster than c3.large at unzipping large blobs to disk. So much for that SSD!
Something Weird Is Going On
It's highly likely that the unzipping work is CPU bound and that most of those, for example, 5 seconds is spent unzipping and only a small margin is the time it takes to write to disk.
If the unzipping CPU work is the dominant "time consumer" why is there a difference at all?!
Or, is the "compute power" the difference between c3 and c4 and disk writes immaterial?
For the record, this test clearly demonstrates that the locally mounted SSD drive is 600% faster than ESB.
c3.large$ dd if=/dev/zero of=/tmp/1gbtest bs=16k count=65536 65536+0 records in 65536+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 16.093 s, 66.7 MB/s c3.large$ sudo dd if=/dev/zero of=/mnt/1gbtest bs=16k count=65536 65536+0 records in 65536+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 2.62728 s, 409 MB/s
Let's try again. But instead of using c4.large and c3.large, let's use the beefier c4.4xlarge and c3.4xlarge. Both have 16 vCPUs.
c4.4xlarge
c4.4xlarge$ python3 fastest-dumper.py /tmp/massive-symbol-zips 130.6MB/s 553.6MB 4.238s 149.2MB/s 297.0MB 1.991s 129.1MB/s 529.8MB 4.103s 116.8MB/s 407.1MB 3.486s 147.3MB/s 306.1MB 2.077s 151.9MB/s 248.2MB 1.634s 140.8MB/s 292.3MB 2.076s 146.8MB/s 288.0MB 1.961s 142.2MB/s 321.0MB 2.257s Average speed: 139.4MB/s Median speed: 142.2MB/s Average files created: 148 Average directories created: 117
c3.4xlarge
c3.4xlarge$ python3 fastest-dumper.py -t /mnt/extracthere /tmp/massive-symbol-zips 95.1MB/s 502.4MB 5.285s 104.1MB/s 303.5MB 2.916s 115.5MB/s 313.9MB 2.718s 105.5MB/s 517.4MB 4.904s 114.1MB/s 288.1MB 2.526s 103.3MB/s 555.9MB 5.383s 114.0MB/s 288.0MB 2.526s 109.2MB/s 251.2MB 2.300s 108.0MB/s 291.0MB 2.693s Average speed: 107.6MB/s Median speed: 108.0MB/s Average files created: 150 Average directories created: 119
What's going on!? The time it takes to unzip and write to disk is, on average, the same for c3.large as c3.4xlarge!
Is Go Any Faster?
I need a break. As mentioned above, the unzip command line program is not any better than doing it in Python. But Go is faster right? Right?
Please first accept that I'm not a Go programmer even though I can use it to build stuff but really my experience level is quite shallow.
Here's the Go version. Critical function that does the unzipping and extraction to disk here:
func DumpAndExtract(dest string, buffer []byte, name string) {
size := int64(len(buffer))
zipReader, err := zip.NewReader(bytes.NewReader(buffer), size)
if err != nil {
log.Fatal(err)
}
for _, f := range zipReader.File {
rc, err := f.Open()
if err != nil {
log.Fatal(err)
}
defer rc.Close()
fpath := filepath.Join(dest, f.Name)
if f.FileInfo().IsDir() {
os.MkdirAll(fpath, os.ModePerm)
} else {
// Make File
var fdir string
if lastIndex := strings.LastIndex(fpath, string(os.PathSeparator)); lastIndex > -1 {
fdir = fpath[:lastIndex]
}
err = os.MkdirAll(fdir, os.ModePerm)
if err != nil {
log.Fatal(err)
}
f, err := os.OpenFile(
fpath, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, f.Mode())
if err != nil {
log.Fatal(err)
}
defer f.Close()
_, err = io.Copy(f, rc)
if err != nil {
log.Fatal(err)
}
}
}
}
And the measurement is done like this:
size := int64(len(content))
t0 := time.Now()
DumpAndExtract(tmpdir, content, filename)
t1 := time.Now()
speed := float64(size) / t1.Sub(t0).Seconds()
It's not as sophisticated (since it's only able to use /tmp) but let's just run it see how it compares to Python:
c4.4xlarge$ mkdir ~/GO c4.4xlarge$ export GOPATH=~/GO c4.4xlarge$ go get github.com/pyk/byten c4.4xlarge$ go build unzips.go c4.4xlarge$ ./unzips /tmp/massive-symbol-zips 56MB/s 407MB 7.27804954 74MB/s 321MB 4.311504933 75MB/s 288MB 3.856798853 75MB/s 292MB 3.90972474 81MB/s 248MB 3.052652168 58MB/s 530MB 9.065985117 59MB/s 554MB 9.35237202 75MB/s 297MB 3.943132388 74MB/s 306MB 4.147176578 Average speed: 70MB/s Median speed: 81MB/s
So... Go is, on average, 40% slower than Python in this scenario. Did not expect that.
In Conclusion
No conclusion. Only confusion.
I thought this would be a lot clearer and more obvious. Yeah, I know it's crazy to measure two things at the same time (unzip and disk write) but the whole thing started with a very realistic problem that I'm trying to solve. The ultimate question was; will the performance benefit from us moving the web servers from AWS EC2 c4.large to c3.large and I think the answer is no.
UPDATE (Nov 30, 2017)
Here's a horrible hack that causes the extraction to always go to /dev/null:
class DevNullZipFile(zipfile.ZipFile):
def _extract_member(self, member, targetpath, pwd):
# member.is_dir() only works in Python 3.6
if member.filename[-1] == '/':
return targetpath
dest = '/dev/null'
with self.open(member, pwd=pwd) as source, open(dest, "wb") as target:
shutil.copyfileobj(source, target)
return targetpath
def dump_and_extract(root_dir, file_buffer, klass):
zf = klass(file_buffer)
zf.extractall(root_dir)
And here's the outcome of running that:
c4.4xlarge$ python3 fastest-dumper.py --dev-null /tmp/massive-symbol-zips 170.1MB/s 297.0MB 1.746s 168.6MB/s 306.1MB 1.815s 147.1MB/s 553.6MB 3.765s 132.1MB/s 407.1MB 3.083s 145.6MB/s 529.8MB 3.639s 175.4MB/s 248.2MB 1.415s 163.3MB/s 321.0MB 1.965s 162.1MB/s 292.3MB 1.803s 168.5MB/s 288.0MB 1.709s Average speed: 159.2MB/s Median speed: 163.3MB/s Average files created: 0 Average directories created: 0
I ran it a few times to make sure the numbers are stable. They are. This is on the c4.4xlarge.
So, the improvement of writing to /dev/null instead of the ESB /tmp is 15%. Kinda goes to show how much of the total time is spent reading the ZipInfo file object.
For the record, the same comparison on the c3.4xlarge was 30% improvement when using /dev/null.
Also for the record, if I replace that line shutil.copyfileobj(source, target) above with pass, the average speed goes from 159.2MB/s to 112.8GB/s but that's not a real value of any kind.
UPDATE (Nov 30, 2017)
Here's the same benchmark using c5.4xlarge instead. So, still EBS but...
"3.0 GHz Intel Xeon Platinum processors with new Intel Advanced Vector Extension 512 (AVX-512) instruction set"
Let's run it on this supposedly faster CPU:
c5.4xlarge$ python3 fastest-dumper.py /tmp/massive-symbol-zips 165.6MB/s 314.6MB 1.900s 163.3MB/s 287.7MB 1.762s 155.2MB/s 278.6MB 1.795s 140.9MB/s 513.2MB 3.643s 137.4MB/s 556.9MB 4.052s 134.6MB/s 531.0MB 3.946s 165.7MB/s 314.2MB 1.897s 158.1MB/s 301.5MB 1.907s 151.6MB/s 253.8MB 1.674s 146.9MB/s 502.7MB 3.422s 163.7MB/s 288.0MB 1.759s Average speed: 153.0MB/s Median speed: 155.2MB/s Average files created: 150 Average directories created: 119
So that is, on average, 10% faster than c4.4xlarge.
Is it 10% more expensive? For a 1-year reserved instance, it's $0.796 versus $0.68 respectively. I.e. 15% more expensive. In other words, in this context it's 15% more $$$ for 10% more processing power.
UPDATE (Jan 24, 2018)
I can almost not believe it!
Thanks you Oliver who discovered (see comment below) a blaring mistake in my last conclusion. The for reserved instances (which is what we use on my Mozilla production servers) the c5.4xlarge is actually cheaper than c4.4xlarge. What?!
In my previous update I compared c4.4xlarge and c5.4xlarge and concluded that c5.4xlarge is 10% faster but 15% more expensive. That actually made sense. Fancier servers, more $$$. But it's not like that in the real world. See for yourself:
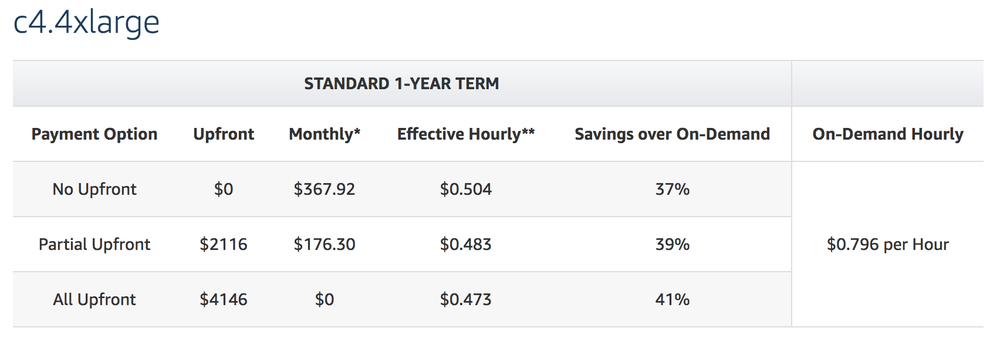
c4.4xlarge
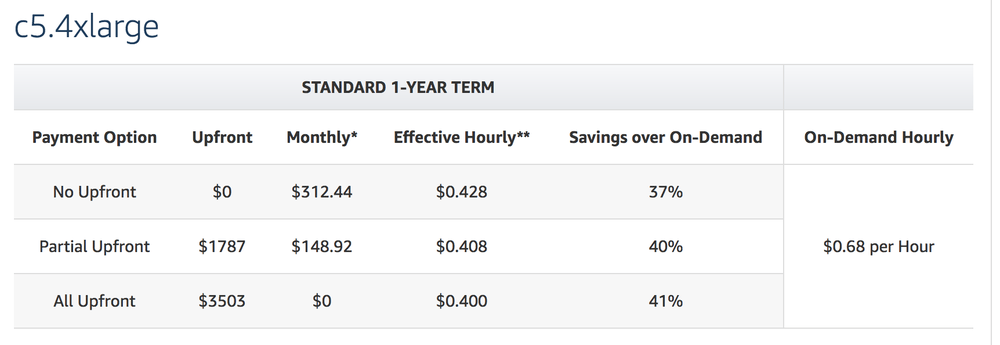
c5.4xlarge
Comments
Post your own commentI think what you are seeing is the extra 100Mhz and possibly turbo from the E5-2666 v3 in the c4 vs the E5-2680 v2 in the c3
I have no idea what that means.
Silly me. I see what you mean. I was on my mobile, tired, when you read that. By the way, see the (second) update above about using c5 instead.
Oooh, good stuff in the update
Rule of thumb: newer instance types are generally faster. Try C5 instance.
Looks like Python script can't use all cores and you just benchmarking single core performance.
Yeah. Which makes sense. For zip files, the whole thing can't be subdivided. In other words, c4.large==c4.Nxlarge
See my (second) update about using c5.
So looking at http://www.cpu-world.com/Compare/416/Intel_Xeon_E5-2666_v3_vs_Intel_Xeon_E5-2680_v2.html the processor in the c4 is a newer generation, which has CPU speed benefits as Mike Lowe points out, but the potentially more significant points may be the added support for DDR4, if Amazon are taking advantage of this, and the new instructions, if the underlying zip library is able to use them.
See (second) update above about the use of c5.4xlarge in comparison to c4.4xlarge.
Did you check with vmstat or top or some other tool what the bottleneck seems to be?
I did not. How do you suggest I do that? Tips welcome.
SSH into the server, run `vmstat 10` (to get an update every 10 seconds), run your benchmark in a different SSH session, then watch vmstat's columns while the benchmark is running.
The last few columns show CPU usage: user, system, idle, wait, stolen.
If User is near 100 all the time, the bottleneck is CPU. If Wait is near 100, then the bottleneck is disk I/O. I would expect System, Idle and Stolen to be near 0, and it would be a very interesting data point if that's not the case. (System is also CPU usage, except in the kernel -- but you're doing compression in userspace, so shouldn't be happening. Idle is idle, which sometimes means blocked waiting on the network -- but you're not doing network I/O here,, right? Wait, I got confused -- you using network-mounted EBS volumes? Anyway. Stolen is CPU time used by the hypervisor and other virtual machines on the same physical host.)
Will try next time I'm at work.
You should try to put the writer part into a separate thread, because the writer blocks until data is written.
If you've 2 separate threads then read and write can run in parallel.
Something like:
q =deque()
with zipfile.ZipFile(pathname) as Z:
for name in Z.namelist():
q.append((name, Z.read(name)))
----
In the writer thread:
while bRun:
if not q:
time.sleep(0.01)
continue
name, data = q.popleft()
with open(name, "wb") as O:
O.write(data)
O.flush()
At least on the incredibly ugly Windows this helps a lot. Especially on Windows it is necessary to have a pool of writer threads to get at least a speed which is comparable to Linux.
Might be tricky. Since the zipfile.ZipFile ultimately does the extraction with happens with shutil.copyfileobj
https://github.com/python/cpython/blob/master/Lib/zipfile.py#L1551
So you can't read the data in thread and send it to another. Unless you can do a prototype.
"Is it 10% more expensive? For a 1-year reserved instance, it's $0.796 versus $0.68 respectively. I.e. 15% more expensive. In other words, in this context it's 15% more $$$ for 10% more processing power."
Do you mean 15% cheaper? c5.4xlarge is $0.68 while c4.4xlarge is $0.796
Wow wow wow!
You are sooo right. It's cheaper to get the faster compute instance.
This is so helpful and also i thought of sharing some information on Amazon Ec2 Instance types comparison Url: https://mindmajix.com/amazon-ec2-instance-comparison
Hai,
Thanks for sharing nice information i Hope this blog is useful for you. https://mindmajix.com/amazon-ec2-instance-comparison. Nice blog and definetly you will get some more information. Please go through it.