tl;dr; If you know that the only I/O you have is disk and the disk is SSD, then synchronous is probably more convenient, faster, and more memory lean.
I'm not a NodeJS expert so I could really do with some eyes on this.
There is little doubt in my mind that it's smart to use asynchronous ideas when your program has to wait for network I/O. Because network I/O is slow, it's better to let your program work on something else whilst waiting. But disk is actually fast. Especially if you have SSD disk.
The context
I'm working on a Node program that walks a large directory structure and looks for certain file patterns, reads those files, does some processing and then exits. It's a cli basically and it's supposed to work similar to jest where you tell it to go and process files and if everything worked, exit with 0 and if anything failed, exit with something >0. Also, it needs to be possible to run it so that it exits immediately on the first error encountered. This is similar to running jest --bail.
My program needs to process thousands of files and although there are thousands of files, they're all relatively small. So first I wrote a simple reference program: https://github.com/peterbe/megafileprocessing/blob/master/reference.js
What it does is that it walks a directory looking for certain .json files that have certain keys that it knows about. Then, just computes the size of the values and tallies that up. My real program will be very similar except it does a lot more with each .json file.
You run it like this:
▶ CHAOS_MONKEY=0.001 node reference.js ~/stumptown-content/kumadocs -q
Error: Chaos Monkey!
at processDoc (/Users/peterbe/dev/JAVASCRIPT/megafileprocessing/reference.js:37:11)
at /Users/peterbe/dev/JAVASCRIPT/megafileprocessing/reference.js:80:21
at Array.forEach (<anonymous>)
at main (/Users/peterbe/dev/JAVASCRIPT/megafileprocessing/reference.js:78:9)
at Object.<anonymous> (/Users/peterbe/dev/JAVASCRIPT/megafileprocessing/reference.js:99:20)
at Module._compile (internal/modules/cjs/loader.js:956:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:973:10)
at Module.load (internal/modules/cjs/loader.js:812:32)
at Function.Module._load (internal/modules/cjs/loader.js:724:14)
at Function.Module.runMain (internal/modules/cjs/loader.js:1025:10)
Total length for 4057 files is 153953645
1 files failed.
(The environment variable CHAOS_MONKEY=0.001 makes it so there's a 0.1% chance it throws an error)
It processed 4,057 files and one of those failed (thanks to the "chaos monkey").
In its current state that (on my MacBook) that takes about 1 second.
It's not perfect but it's a good skeleton. Everything is synchronous. E.g.
function main(args) {
// By default, don't exit if any error happens
const { bail, quiet, root } = parseArgs(args);
const files = walk(root, ".json");
let totalTotal = 0;
let errors = 0;
files.forEach(file => {
try {
const total = processDoc(file, quiet);
!quiet && console.log(`${file} is ${total}`);
totalTotal += total;
} catch (err) {
if (bail) {
throw err;
} else {
console.error(err);
errors++;
}
}
});
console.log(`Total length for ${files.length} files is ${totalTotal}`);
if (errors) {
console.warn(`${errors} files failed.`);
}
return errors ? 1 : 0;
}
And inside the processDoc function it used const content = fs.readFileSync(fspath, "utf8");.
I/Os compared
@amejiarosario has a great blog post called "What every programmer should know about Synchronous vs. Asynchronous Code". In it, he has this great bar chart:
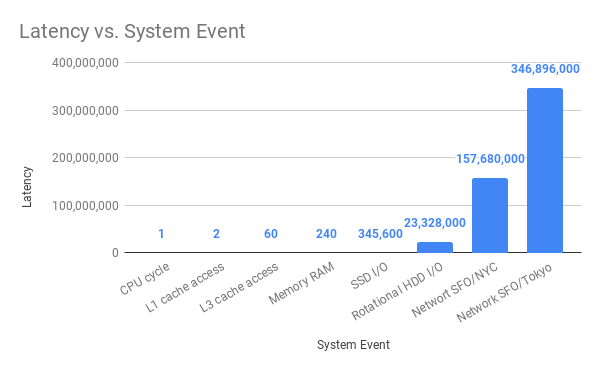
If you compare "SSD I/O" with "Network SFO/NCY" the difference is that SSD I/O is 456 times "faster" than SFO-to-NYC network I/O. I.e. the latency is 456 times less.
Another important aspect when processing lots of files is garbage collection. When running synchronous, it can garbage collect as soon as it has processed one file before moving on to the next. If it was asynchronous, as soon as it yields to move on to the next file, it might hold on to memory from the first file. Why does this matter? Because if the memory-usage when processing many files asynchronously bloat so hard that it actually crashes with an out-of-memory error. So what matters is avoiding that. It's OK if the program can use lots of memory if it needs to, but it's really bad if it crashes.
One way to measure this is to use /usr/bin/time -l (at least that's what it's called on macOS). For example:
▶ /usr/bin/time -l node reference.js ~/stumptown-content/kumadocs -q
Total length for 4057 files is 153970749
0.75 real 0.58 user 0.23 sys
57221120 maximum resident set size
0 average shared memory size
0 average unshared data size
0 average unshared stack size
64160 page reclaims
0 page faults
0 swaps
0 block input operations
0 block output operations
0 messages sent
0 messages received
0 signals received
0 voluntary context switches
1074 involuntary context switches
Its maximum memory usage total was 57221120 bytes (55MB) in this example.
Introduce asynchronous file reading
Let's change the reference implementation to use const content = await fsPromises.readFile(fspath, "utf8");. We're still using files.forEach(file => { but within the loop the whole function is prefixed with async function main() { now. Like this:
async function main(args) {
// By default, don't exit if any error happens
const { bail, quiet, root } = parseArgs(args);
const files = walk(root, ".json");
let totalTotal = 0;
let errors = 0;
let total;
for (let file of files) {
try {
total = await processDoc(file, quiet);
!quiet && console.log(`${file} is ${total}`);
totalTotal += total;
} catch (err) {
if (bail) {
throw err;
} else {
console.error(err);
errors++;
}
}
}
console.log(`Total length for ${files.length} files is ${totalTotal}`);
if (errors) {
console.warn(`${errors} files failed.`);
}
return errors ? 1 : 0;
}
Let's see how it works:
▶ /usr/bin/time -l node async1.js ~/stumptown-content/kumadocs -q
Total length for 4057 files is 153970749
1.31 real 1.01 user 0.49 sys
68898816 maximum resident set size
0 average shared memory size
0 average unshared data size
0 average unshared stack size
68107 page reclaims
0 page faults
0 swaps
0 block input operations
0 block output operations
0 messages sent
0 messages received
0 signals received
0 voluntary context switches
62562 involuntary context switches
That means it maxed out at 68898816 bytes (65MB).
You can already see a difference. 0.79 seconds and 55MB for synchronous and 1.31 seconds and 65MB for asynchronous.
But to really measure this, I wrote a simple Python program that runs this repeatedly and reports a min/median on time and max on memory:
▶ python3 wrap_time.py /usr/bin/time -l node reference.js ~/stumptown-content/kumadocs -q ... TIMES BEST: 0.74s WORST: 0.84s MEAN: 0.78s MEDIAN: 0.78s MAX MEMORY BEST: 53.5MB WORST: 55.3MB MEAN: 54.6MB MEDIAN: 54.8MB
And for the asynchronous version:
▶ python3 wrap_time.py /usr/bin/time -l node async1.js ~/stumptown-content/kumadocs -q ... TIMES BEST: 1.28s WORST: 1.82s MEAN: 1.39s MEDIAN: 1.31s MAX MEMORY BEST: 65.4MB WORST: 67.7MB MEAN: 66.7MB MEDIAN: 66.9MB
Promise.all version
I don't know if the async1.js is realistic. More realistically you'll want to not wait for one file to be processed (asynchronously) but start them all at the same time. So I made a variation of the asynchronous version that looks like this instead:
async function main(args) {
// By default, don't exit if any error happens
const { bail, quiet, root } = parseArgs(args);
const files = walk(root, ".json");
let totalTotal = 0;
let errors = 0;
let values;
values = await Promise.all(
files.map(async file => {
try {
total = await processDoc(file, quiet);
!quiet && console.log(`${file} is ${total}`);
return total;
} catch (err) {
if (bail) {
console.error(err);
process.exit(1);
} else {
console.error(err);
errors++;
}
}
})
);
totalTotal = values.filter(n => n).reduce((a, b) => a + b);
console.log(`Total length for ${files.length} files is ${totalTotal}`);
if (errors) {
console.warn(`${errors} files failed.`);
throw new Error("More than 0 errors");
}
}
You can see the whole file here: async2.js
The key difference is that it uses await Promise.all(files.map(...)) instead of for (let file of files) {.
Also, to accomplish the ability to bail on the first possible error it needs to use process.exit(1); within the callbacks. Not sure if that's right but from the outside, you get the desired effect as a cli program. Let's measure it too:
▶ python3 wrap_time.py /usr/bin/time -l node async2.js ~/stumptown-content/kumadocs -q ... TIMES BEST: 1.44s WORST: 1.61s MEAN: 1.52s MEDIAN: 1.52s MAX MEMORY BEST: 434.0MB WORST: 460.2MB MEAN: 453.4MB MEDIAN: 456.4MB
Note how this uses almost 10x max. memory. That's dangerous if the processing is really memory hungry individually.
When asynchronous is right
In all of this, I'm assuming that the individual files are small. (Roughly, each file in my experiment is about 50KB)
What if the files it needs to read from disk are large?
As a simple experiment read /users/peterbe/Downloads/Keybase.dmg 20 times and just report its size:
for (let x = 0; x < 20; x++) {
fs.readFile("/users/peterbe/Downloads/Keybase.dmg", (err, data) => {
if (err) throw err;
console.log(`File size#${x}: ${Math.round(data.length / 1e6)} MB`);
});
}
See the simple-async.js here. Basically it's this:
for (let x = 0; x < 20; x++) {
fs.readFile("/users/peterbe/Downloads/Keybase.dmg", (err, data) => {
if (err) throw err;
console.log(`File size#${x}: ${Math.round(data.length / 1e6)} MB`);
});
}
Results are:
▶ python3 wrap_time.py /usr/bin/time -l node simple-async.js ... TIMES BEST: 0.84s WORST: 4.32s MEAN: 1.33s MEDIAN: 0.97s MAX MEMORY BEST: 1851.1MB WORST: 3079.3MB MEAN: 2956.3MB MEDIAN: 3079.1MB
And the equivalent synchronous simple-sync.js here.
for (let x = 0; x < 20; x++) {
const largeFile = fs.readFileSync("/users/peterbe/Downloads/Keybase.dmg");
console.log(`File size#${x}: ${Math.round(largeFile.length / 1e6)} MB`);
}
It performs like this:
▶ python3 wrap_time.py /usr/bin/time -l node simple-sync.js ... TIMES BEST: 1.97s WORST: 2.74s MEAN: 2.27s MEDIAN: 2.18s MAX MEMORY BEST: 1089.2MB WORST: 1089.7MB MEAN: 1089.5MB MEDIAN: 1089.5MB
So, almost 2x as slow but 3x as much max. memory.
Lastly, instead of an iterative loop, let's start 20 readers at the same time (simple-async2.js):
Promise.all(
[...Array(20).fill()].map((_, x) => {
return fs.readFile("/users/peterbe/Downloads/Keybase.dmg", (err, data) => {
if (err) throw err;
console.log(`File size#${x}: ${Math.round(data.length / 1e6)} MB`);
});
})
);
And it performs like this:
▶ python3 wrap_time.py /usr/bin/time -l node simple-async2.js ... TIMES BEST: 0.86s WORST: 1.09s MEAN: 0.96s MEDIAN: 0.94s MAX MEMORY BEST: 3079.0MB WORST: 3079.4MB MEAN: 3079.2MB MEDIAN: 3079.2MB
So quite naturally, the same total time as the simple async version but uses 3x max. memory every time.
Ergonomics
I'm starting to get pretty comfortable with using promises and async/await. But I definitely feel more comfortable without. Synchronous programs read better from an ergonomics point of view. The async/await stuff is just Promises under the hood and it's definitely an improvement but the synchronous versions just have a simpler "feeling" to it.
Conclusion
I don't think it's a surprise that the overhead of event switching adds more time than its worth when the individual waits aren't too painful.
A major flaw with synchronous programs is that they rely on the assumption that there's no really slow I/O. So what if the program grows and morphs so that it someday does depend on network I/O then your synchronous program is "screwed" since an asynchronous version would run circles around it.
The general conclusion is; if you know that the only I/O you have is disk and the disk is SSD, then synchronous is probably more convenient, faster, and more memory lean.
Comments
This is consistent with my own tests on the subject. It's ironic, because in the Node.js world there's a sort of "cult of async", where people are told to use async for everything, without thinking about it.