Did you see my blog post about Decorated Concurrency - Python multiprocessing made really really easy? If not, fear not. There, I'm demonstrating how I take a task of creating 100 thumbnails from a large JPG. First in serial, then concurrently, with a library called deco. The total time to get through the work massively reduces when you do it concurrently. No surprise. But what's interesting is that each individual task takes a lot longer. Instead of 0.29 seconds per image it took 0.65 seconds per image (...inside each dedicated processor).
The simple explanation, even from a layman like myself, must be that when doing so much more, concurrently, the whole operating system struggles to keep up with other little subtle tasks.
With deco you can either let Python's multiprocessing just use as many CPUs as your computer has (8 in the case of my Macbook Pro) or you can manually set it. E.g. @concurrent(processes=5) would spread the work across a max of 5 CPUs.
So, I ran my little experiment again for every number from 1 to 8 and plotted the results:
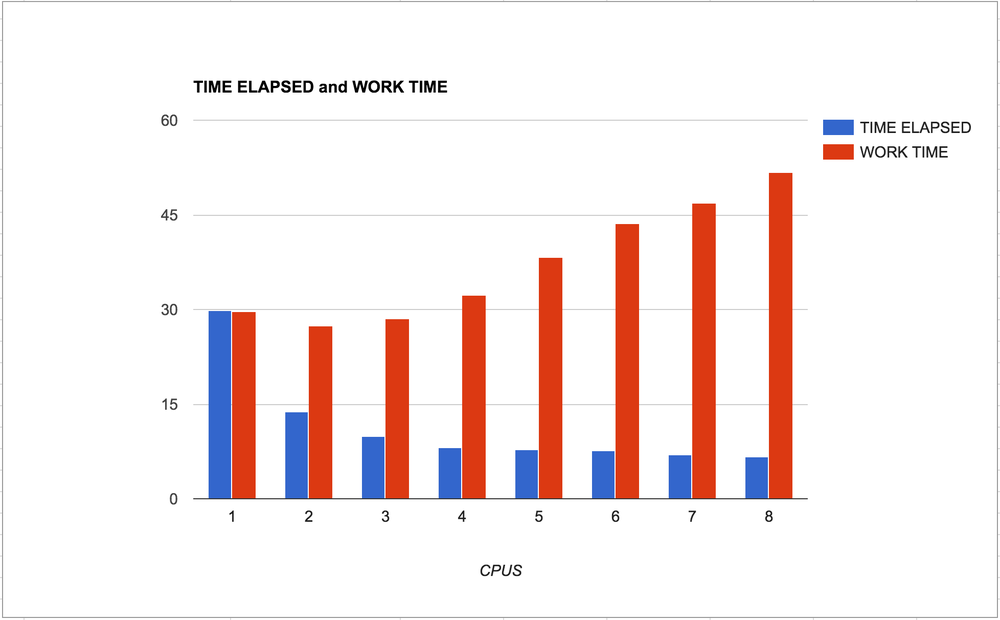
What to take away...
The blue bars is the time it takes, in total, from starting the program till the program ends. The lower the better.
The red bars is the time it takes, in total, to complete each individual task.
Meaning, when the number of CPUs is low you have to wait longer for all the work to finish and when the number of CPUs is high the computer needs more time to finish its work. This is an insight into over-use of operating system resources.
If the work is much much more demanding than this experiment (the JPG is only 3.3Mb and one thumbnail only takes 0.3 seconds to make) you might have a red bar on the far right that is too expensive for your server. Or worse, it might break things so that everything stops.
In conclusion...
Choose wisely. Be aware how "bound" the task is.
Also, remember that if the work of each individual task is too "light", the overhead of messing with multprocessing might actually cost more than it's worth.
The code
Here's the messy code I used:
import time
from PIL import Image
from deco import concurrent, synchronized
import sys
processes = int(sys.argv[1])
assert processes >= 1
assert processes <= 8
@concurrent(processes=processes)
def slow(times, offset):
t0 = time.time()
path = '9745e8.jpg'
img = Image.open(path)
size = (100 + offset * 20, 100 + offset * 20)
img.thumbnail(size, Image.ANTIALIAS)
img.save('thumbnails/{}.jpg'.format(offset), 'JPEG')
t1 = time.time()
times[offset] = t1 - t0
@synchronized
def run(times):
for index in range(100):
slow(times, index)
t0 = time.time()
times = {}
run(times)
t1 = time.time()
print "TOOK", t1-t0
print "WOULD HAVE TAKEN", sum(times.values())
UPDATE
I just wanted to verify that the experiment is valid that proves that CPU bound work hogs resources acorss CPUs that affects their individual performance.
Let's try to the similar but totally different workload of a Network bound task. This time, instead of resizing JPEGs, it waits for finishing HTTP GET requests.
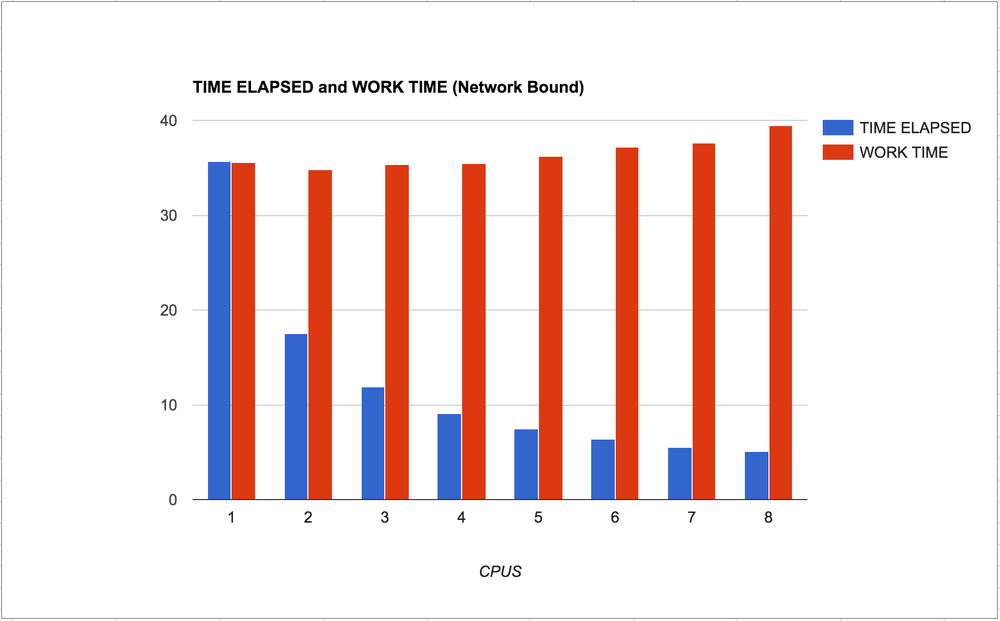
So clearly it makes sense. The individual work withing each process is not generally slowed down much. A tiny bit, but not much. Also, I like the smoothness of the curve of the blue bars going from left to right. You can clearly see that it's reverse logarithmic.
Comments
Using a dict -specialty passing it around- to do the timing bookkeeping can be costly. Possibly that has more effect on the graphs than expected.
Returning the time (as int) and storing it in run function- even in the dict- can speed. And give more objective results.
Does your MacBook have 4 cores with hyperthreading? If so that explains why the effect peters out at 4 processes. If the task is CPU-bound then hyperthreading generally does not offer a big performance boost.
I don't know. It's just a standard Macbook Pro.