Suppose you have a bunch of files you need to Gzip in Python; what's the optimal way to do that? In serial, to avoid saturating the GIL? In multiprocessing, to spread the load across CPU cores? Or with threads?
I needed to know this for symbols.mozilla.org since it does a lot of Gzip'ing. In symbols.mozilla.org clients upload a zip file full of files. A lot of them are plain text and when uploaded to S3 it's best to store them gzipped. Basically it does this:
def upload_sym_file(s3_client, payload, bucket_name, key_name):
file_buffer = BytesIO()
with gzip.GzipFile(fileobj=file_buffer, mode='w') as f:
f.write(payload)
file_buffer.seek(0, os.SEEK_END)
size = file_buffer.tell()
file_buffer.seek(0)
s3_client.put_object(
Bucket=bucket_name,
Key=key_name,
Body=file_buffer
)
print(f"Uploaded {size}")
Another important thing to consider before jumping into the benchmark is to appreciate the context of this application; the bundles of files I need to gzip are often many but smallish. The average file size of the files that need to be gzip'ed is ~300KB. And each bundle is between 5 to 25 files.
The Benchmark
For the sake of the benchmark, here, all it does it figure out the size of each gzipped buffer and reports that as a list.
f1 - Basic serial
def f1(payloads):
sizes = []
for payload in payloads:
sizes.append(_get_size(payload))
return sizes
f2 - Using multiprocessing.Pool
def f2(payloads): # multiprocessing
sizes = []
with multiprocessing.Pool() as p:
sizes = p.map(_get_size, payloads)
return sizes
f3 - Using concurrent.futures.ThreadPoolExecutor
def f3(payloads): # concurrent.futures.ThreadPoolExecutor
sizes = []
futures = []
with concurrent.futures.ThreadPoolExecutor() as executor:
for payload in payloads:
futures.append(
executor.submit(
_get_size,
payload
)
)
for future in concurrent.futures.as_completed(futures):
sizes.append(future.result())
return sizes
f4 - Using concurrent.futures.ProcessPoolExecutor
def f4(payloads): # concurrent.futures.ProcessPoolExecutor
sizes = []
futures = []
with concurrent.futures.ProcessPoolExecutor() as executor:
for payload in payloads:
futures.append(
executor.submit(
_get_size,
payload
)
)
for future in concurrent.futures.as_completed(futures):
sizes.append(future.result())
return sizes
Note that when using asynchronous methods like this, the order of items returned is not the same as they're submitted. An easy remedy if you need the results back in order is to not use a list but to use a dictionary. Then you can track each key (or index if you like) to a value.
The Results
I ran this on three different .zip files of different sizes. To get some sanity in the benchmark I made it print out how many bytes it has to process and how many bytes the gzip will manage to do.
# files 66 Total bytes to gzip 140.69MB Total bytes gzipped 14.96MB Total bytes shaved off by gzip 125.73MB # files 103 Total bytes to gzip 331.57MB Total bytes gzipped 66.90MB Total bytes shaved off by gzip 264.67MB # files 26 Total bytes to gzip 86.91MB Total bytes gzipped 8.28MB Total bytes shaved off by gzip 78.63MB
Sorry for being eastetically handicapped when it comes to using Google Docs but here goes...
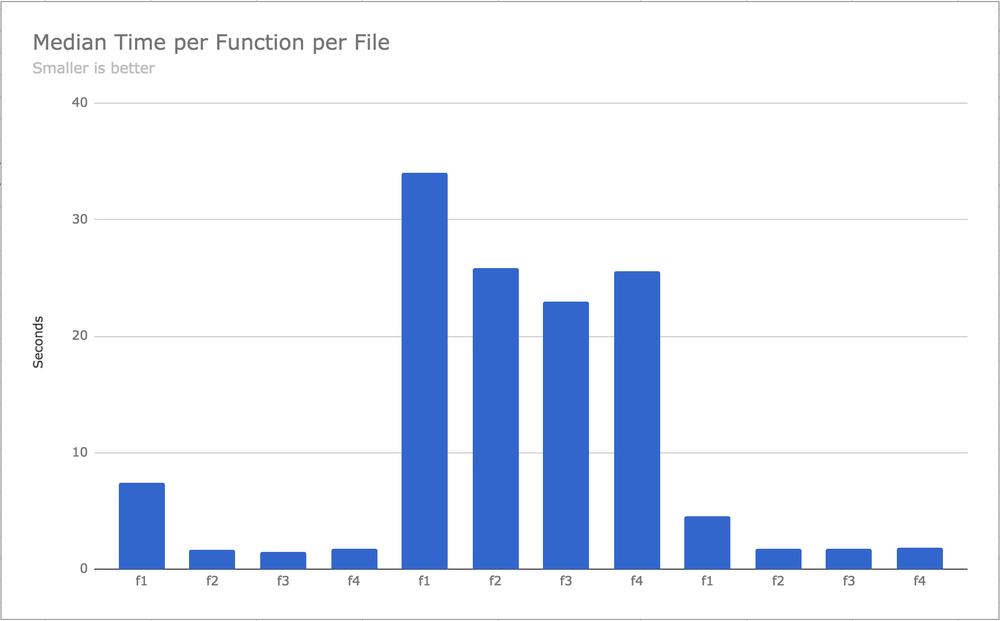
This demonstrates the median times it takes each function to complete, each of the three different files.
In all three files I tested, clearly doing it serially (f1) is the worst. Supposedly since my laptop has more than one CPU core and the others are not being used. Another pertinent thing to notice is that when the work is really big, (the middle 4 bars) the difference isn't as big doing things serially compared to concurrently.
That second zip file contained a single file that was 80MB. The largest in the other two files were 18MB and 22MB.
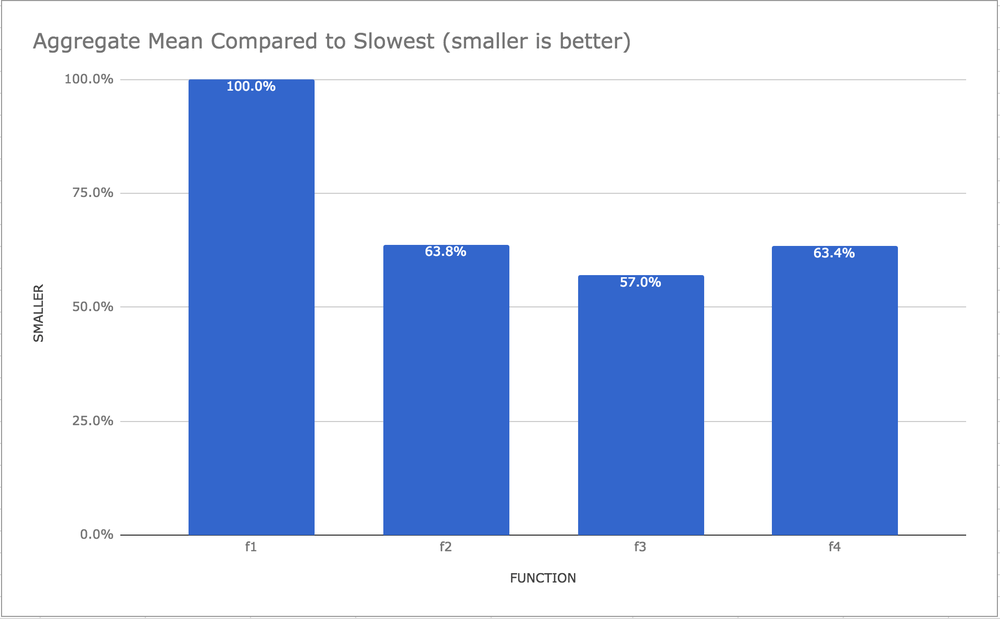
This is the mean across all medians grouped by function and each compared to the slowest.
I call this the "bestest graph". It's a combination across all different sizes and basically concludes which one is the best, which clearly is function f3 (the one using concurrent.futures.ThreadPoolExecutor).
CPU Usage
This is probably the best way to explain how the CPU is used; I ran each function repeatedly, then opened gtop and took a screenshot of the list of processes sorted by CPU percentage.
f1 - Serially
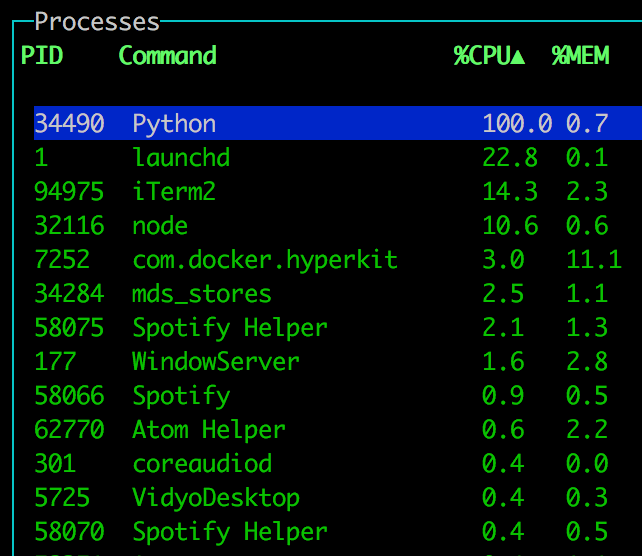
No distractions but it takes 100% of one CPU to work.
f2 - multiprocessing.Pool
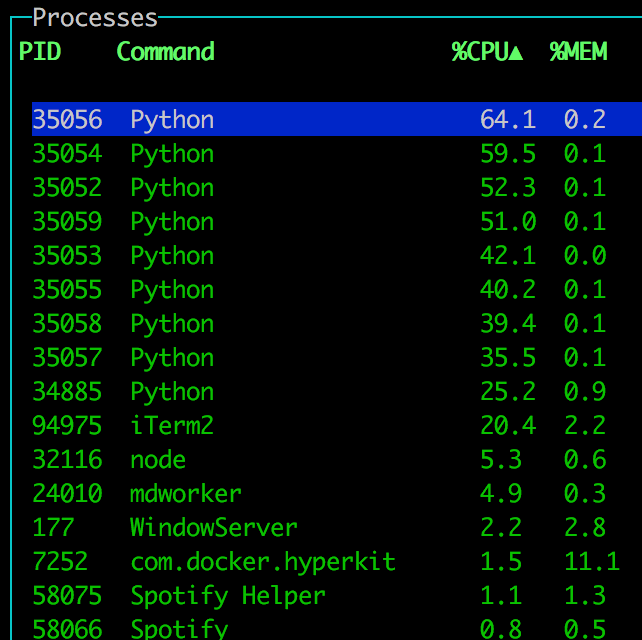
My laptop has 8 CPU cores, but I don't know why I see 9 Python processes here.
I don't know why each CPU isn't 100% but I guess there's some administrative overhead to start processes by Python.
f3 - concurrent.futures.ThreadPoolExecutor
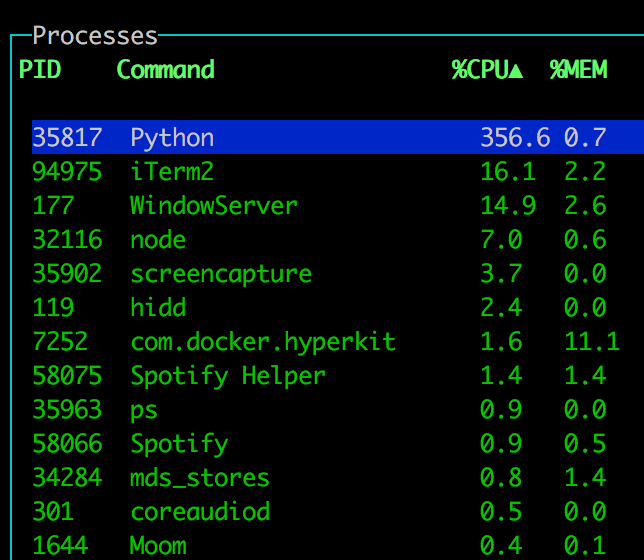
One process, with roughly 5 x 8 = 40 threads GIL swapping back and forth but all in all it manages to keep itself very busy since threads are lightweight to share data to.
f4 - concurrent.futures.ProcessPoolExecutor
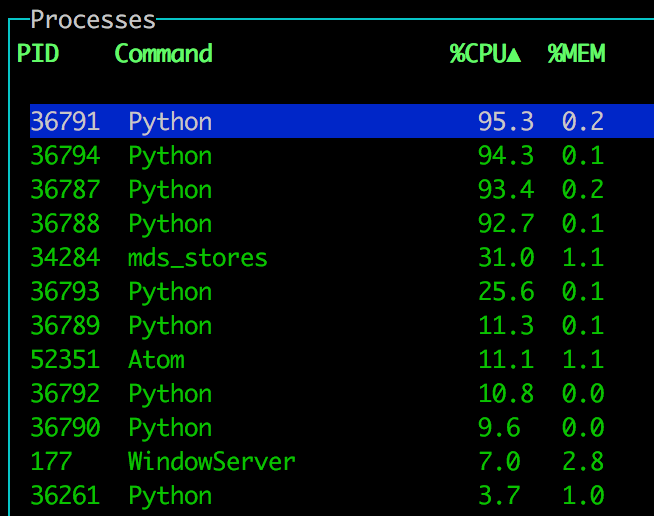
This is actually kinda like multiprocessing.Pool but with a different (arguably easier) API.
Conclusion
By a small margin concurrent.futures.ThreadPoolExecutor won. That's despite not being able to use all CPU cores. This, pseudo scientifically, proves that the overhead of starting the threads is (remember average number of files in each .zip is ~65) more worth it than being able to use all CPUs.
Discussion
There's an interesting twist to this! At least for my use case...
In the application I'm working on, there's actually a lot more that needs to be done other than just gzip'ping some blobs of files. For each file I need to a HEAD query to AWS S3 and an PUT query to AWS S3 too. So what I actually need to do is create an instance of client = botocore.client.S3 that I use to call client.list_objects_v2 and client.put_object.
When you create an instance of botocore.client.S3, automatically botocore will instanciate itself with credentials from os.environ['AWS_ACCESS_KEY_ID'] etc. (or read from some /.aws file). Once created, if you ask it to do many different network operations, internally it relies on urllib3.poolmanager.PoolManager which is a list of 10 HTTP connections that get reused.
So when you run the serial version you can re-use the client instance for every file you process but you can only use one HTTP connection in the pool. With the concurrent.futures.ThreadPoolExecutor it can not only re-use the same instance of botocore.client.S3 it can cycle through all the HTTP connections in the pool.
The process based alternatives like multiprocessing.Pool and concurrent.futures.ProcessPoolExecutor can not re-use the botocore.client.S3 instance since it's not pickle'able. And it has to create a new HTTP connection for every single file.
So, the conclusion of the above rambling is that concurrent.futures.ThreadPoolExecutor is really awesome! Not only did it perform excellently in the Gzip benchmark, it has the added bonus that it can share instance objects and HTTP connections.
Comments
Post your own commentWhat was the size of the largest file in each of the input data sets? Since you don't parallelize compression of individual files, the distribution of file sizes (as well as luck re: which executor gets which file, since there may be less executors than files) has a large effect on the compression duration. Especially in the second data set I suspect a single large file dominates the compression time.
It would be interesting to see a speed comparison with tar + pigz (https://zlib.net/pigz/) and maybe tar + pixz (https://github.com/vasi/pixz)
Largest file, in the largest .zip file, was 219MB.
That file contained some few HUGE ones (see above), the mean 3.2MB but the median 195KB.
Will take a look at pigz but I'm probably not going to consider it seriously since it's not on PyPI.
Oh, pigz isn't a Python module. It compiles to a binary executable. So, without actually attempting to write and new benchmarks I can fairly confidently predict that it won't be a success. The overheads of creating and managing subprocesses will just take too much precious time.
Why not upload directly to S3?! I believe you can gzip clientside before uploading?
Lots of reasons. If it was an option, we'd go for it.
That's what we do for another app where the server pre-signs a URL for the client to upload directly to.
Cool, what are those reasons?
According to python doc (https://docs.python.org/3/c-api/init.html#releasing-the-gil-from-extension-code), compressing with zlib (which is used by gzip library) releases GIL during the process. Therefore, in ThreadPool case, it does use all CPU cores.
Thanks for taking the time to do the test and write up the review. f2 and f4 are essentially the same as ProcessPoolExecutor uses the multiprocessing library. I'm not sure about the three different runs with such variance of sizes helps in the bar chart; would help to group the functions together. It does, however, look like the performance improvements decrease with the size of the file which is counter intuitive unless you're hitting an I/O bottleneck?
You get 9 processes because you're spawning 8 from the parent, which then sits doing nothing while the children work.
I'd be fascinated to see if there's a difference (hopefully, further improvement) running under my own ScalingPoolExecutor: https://github.com/marrow/util/blob/develop/marrow/util/futures.py?ts=4#L64 — this is a tweaked ThreadPoolExecutor that does Less Dumb™ on each work unit submission (default thread pool attempts to spawn a thread on each submission regardless of the existence of idle threads), scales the pool size based on pending backlog size, and encourages memory cleanup by limiting the amount of work completed by any given thread.
IMHO should not time the pool creation process by creating pools on init beforehand, being ready like in a webserver. How does it compare in this case?
Do you think it actually makes a difference? It definitely seems like a, by design, smart thing to have all the processes ready. (Isn't it called something like pre-fork in Gunicorn?) But that seems rather beyond the point of the task at hand.