tl;dr There's a new interesting wrapper on Python multiprocessing called deco, written by Alex Sherman and Peter Den Hartog, both at University of Wisconsin - Madison. It makes Python multiprocessing really really easy.
The paper is here (PDF) and the code is here: https://github.com/alex-sherman/deco.
This library is based on something called Pydron which, if I understand it correctly, is still a piece of research with no code released. ("We currently estimate that we will be ready for the release in the first quarter of 2015.")
Apart from using simple decorators on functions, the big difference that deco takes, is that it makes it really easy to get started and that there's a hard restriction on how to gather the results of sub-process calls'. In deco, you pass in a mutable object that has a keyed index (e.g. a python dict). A python list is also mutable but it doesn't have an index. Meaning, you could get race conditions on mylist.append().
"However, DECO does impose one important restriction on the program: all mutations may only by index based."
Some basic example
Just look at this example:
# before.py
def slow(index):
time.sleep(5)
def run():
for index in list('123'):
slow(index)
run()
And when run, you clearly expect it to take 15 seconds:
$ time python before.py real 0m15.090s user 0m0.057s sys 0m0.022s
Ok, let's parallelize this with deco. First pip install deco, then:
# after.py
from deco import concurrent, synchronized
@concurrent
def slow(index):
time.sleep(5)
@synchronized
def run():
for index in list('123'):
slow(index)
run()
And when run, it should be less than 15 seconds:
$ time python after.py real 0m5.145s user 0m0.082s sys 0m0.038s
About the order of execution
Let's put some logging into that slow() function above.
def slow(index):
time.sleep(5)
print 'done with {}'.format(index)
Run the example a couple of times and note that the order is not predictable:
$ python after.py done with 1 done with 3 done with 2 $ python after.py done with 1 done with 2 done with 3 $ python after.py done with 3 done with 2 done with 1
That probably don't come as a surprise for those familiar with async stuff, but it's worth reminding so you don't accidentally depend on order.
@synchronized or .wait()
Remember the run() function in the example above? The @synchronized decorator is magic. It basically figures out that within the function call there are calls out to sub-process work. What it does it that it "pauses" until all those have finished. An alternative approach is to call the .wait() method on the decorated concurrency function:
def run():
for index in list('123'):
slow(index)
slow.wait()
That works the same way. This could potentially be useful if you, on the next line, need to depend on the results. But if that's the case you could just split up the function and slap a @synchronized decorator on the split-out function.
No Fire-and-forget
It might be tempting to not set the @synchronized decorator and not call .wait() hoping the work will be finished anyway somewhere in the background. The functions that are concurrent could be, for example, functions that generate thumbnails from a larger image or something time consuming where you don't care when it finishes, as long as it finishes.
# fireandforget.py
# THIS DOES NOT WORK
# And it's not expected to either.
@concurrent
def slow(index):
time.sleep(5)
def run():
for index in list('123'):
slow(index)
run()
When you run it, you don't get an error:
$ time python fireandforget.py real 0m0.231s user 0m0.079s sys 0m0.047s
But if you dig deeper, you'll find that it never actually executes those concurrent functions.
If you want to do fire-and-forget you need to have another service/process that actually keeps running and waiting for all work to be finished. That's how the likes of a message queue works.
Number of concurrent workers
multiprocessing.Pool automatically, as far as I can understand, figures out how many concurrent jobs it can run. On my Mac, where I have 8 CPUS, the number is 8.
This is easy to demonstrate. In the example above it does exactly 3 concurrent jobs, because len(list('123')) == 3. If I make it 8 items, the whole demo run takes, still, 5 seconds (plus a tiny amount of overhead). If I make it 9 items, it now takes 10 seconds.
How multiprocessing figures this out I don't know but I can't imagine it being anything but a standard lib OS call to ask the operating system how many CPUs it has.
You can actually override this with your own number. It looks like this:
from deco import concurrent
@concurrent(processes=5)
def really_slow_and_intensive_thing():
...
So that way, the operating system doesn't get too busy. It's like a throttle.
A more realistic example
Let's actually use the mutable for something and let's do something that isn't just a time.sleep(). Also, let's do something that is CPU bound. A lot of times where concurrency is useful is when you're network bound because running many network waiting things at the same time doesn't hose the system from being able to do other things.
Here's the code:
from PIL import Image
from deco import concurrent, synchronized
@concurrent
def slow(times, offset):
t0 = time.time()
path = '9745e8.jpg'
img = Image.open(path)
size = (100 + offset * 20, 100 + offset * 20)
img.thumbnail(size, Image.ANTIALIAS)
img.save('thumbnails/{}.jpg'.format(offset), 'JPEG')
t1 = time.time()
times[offset] = t1 - t0
@synchronized
def run(times):
for index in range(100):
slow(times, index)
t0 = time.time()
times = {}
run(times)
t1 = time.time()
print "TOOK", t1-t0
print "WOULD HAVE TAKEN", sum(times.values())
It generates 100 different thumbnails from a very large original JPG. Running this on my macbook pro takes 8.4 seconds but the individual times was a total of 65.1 seconds. The numbers makes sense, because 65 seconds / 8 cores ~= 8 seconds.
But, where it gets really interesting is that if you remove the deco decorators and run 100 thumbnail creations in serial, on my laptop, it takes 28.9 seconds. Now, 28.9 seconds is much more than 8.4 seconds so it's still a win to multiprocessing for this kind of CPU bound work. However, stampeding herd of doing 8 CPU intensive tasks at the same time can put some serious strains on your system. Also, it could cause high spikes in terms of memory allocation that wouldn't have happened if freed space can be re-used in the serial pattern.
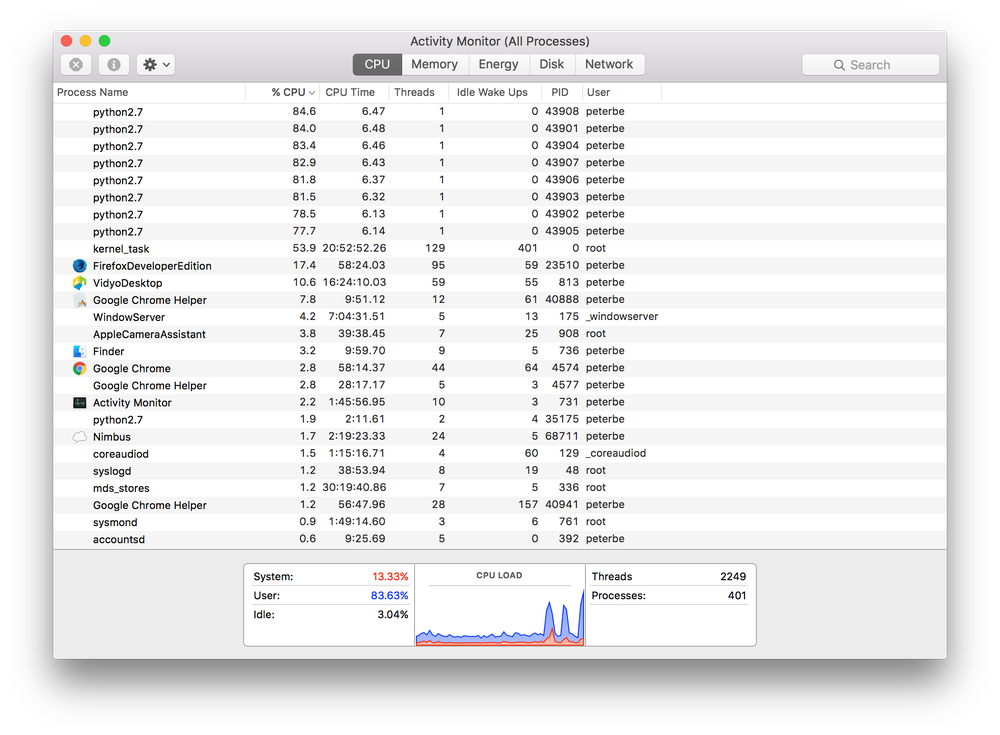
Here's by the way the difference in what this looks like in the Activity Monitor:
Fully concurrent PIL work
Same work but in serial
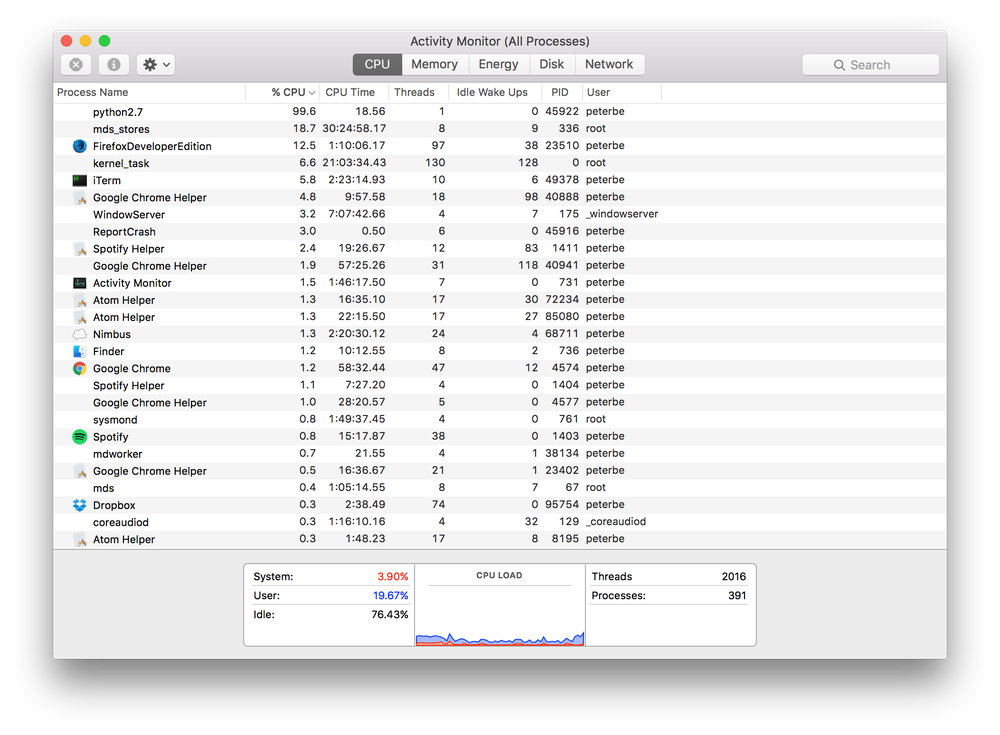
One more "realistic" pattern
Let's do this again with a network bound task. Let's download 100 webpages from my blog. We'll do this by keeping an index where the URL is the key and the value is the time it took to download that one individual URL. This time, let's start with the serial pattern:
(Note! I ran these two experiments a couple of times so that the server-side cache would get a chance to clear out outliers)
import time, requests
urls = """
https://www.peterbe.com/plog/blogitem-040212-1
https://www.peterbe.com/plog/geopy-distance-calculation-pitfall
https://www.peterbe.com/plog/app-for-figuring-out-the-best-car-for-you
https://www.peterbe.com/plog/Mvbackupfiles
...a bunch more...
https://www.peterbe.com/plog/swedish-holidays-explaine
https://www.peterbe.com/plog/wing-ide-versus-jed
https://www.peterbe.com/plog/worst-flash-site-of-the-year-2010
""".strip().splitlines()
assert len(urls) == 100
def download(url, data):
t0 = time.time()
assert requests.get(url).status_code == 200
t1 = time.time()
data[url] = t1-t0
def run(data):
for url in urls:
download(url, data)
somemute = {}
t0 = time.time()
run(somemute)
t1 = time.time()
print "TOOK", t1-t0
print "WOULD HAVE TAKEN", sum(somemute.values()), "seconds"
When run, the output is:
TOOK 35.3457410336 WOULD HAVE TAKEN 35.3454759121 seconds
Now, let's add the deco decorators, so basically these changes:
from deco import concurrent, synchronized
@concurrent
def download(url, data):
t0 = time.time()
assert requests.get(url).status_code == 200
t1 = time.time()
data[url] = t1-t0
@synchronized
def run(data):
for url in urls:
download(url, data)
And the output this time:
TOOK 5.13103795052 WOULD HAVE TAKEN 39.7795288563 seconds
So, instead of it having to take 39.8 seconds it only needed to take 5 seconds with extremely little modification. I call that a win!
What's next
Easy; actually build something that uses this.
Comments
Post your own commentInitially I wondered why does the title say "really really easy". But when I tried - I found that this is "really really really extremely easy". Thanks for this.
I've been waiting for something like this for years! ...and this is much better than I was hoping for.
I've been waiting for something like this for years! ...and this is much better than I was hoping for. Thank you Alex.
On Windows, one should add to imports:
from multiprocessing import freeze_support
and before calling "run", add:
if __name__ == "__main__":
freeze_support()
run()
This looks interesting but I've really appreciated the flexibility of `concurrent.futures` for doing concurrent work in Python. Specifically, I find the `as_completed ` method makes it easy to write code that handles lots of work in parallel without having to handle the results in-order or block waiting for everything to finish: http://pythonhosted.org/futures/#concurrent.futures.as_completed .
Uh?! Can you do fire-and-forget with concurrent.futures?!
Sure, you just call `submit` on the `Executor` you're using:
http://pythonhosted.org/futures/#concurrent.futures.Executor.submit
...and then you can either call `wait` on it to wait for everything to finish, or use it in a with statement, which does that for you.
Wowza! Hot stuff, thanks for sharing :)
Interesting concept.
The github https://github.com/alex-sherman/deco and your article do not mention which versions on Python are required.
Do you have info on that?
Pretty sure it's 2 and 3. At least 3.5.
----
How multiprocessing figures this out I don't know but I can't imagine it being anything but a standard lib OS call to ask the operating system how many CPUs it has.
----
There exists a cpu_count() function. Useful if you want to limit yourself to say, 25% of available cores. I guess it simply calls nprocs on unix.
>>>from multiprocessing import cpu_count
>>>cpu_count() #same as nproc
32
From the docs: (https://docs.python.org/2/library/multiprocessing.html)
multiprocessing.cpu_count()
Return the number of CPUs in the system. May raise NotImplementedError.
so I guess a try..except is in order if you want to use this yourself. Not sure when the NotImplemented triggers, maybe it's a OS-dependent thing.
Clap, Clap, Clap!
I'm so looking forward to using this module. However, I have to use python3 and I'm pretty sure deco is not ready for python3 yet:
Traceback (most recent call last):
File "./decotest", line 17, in <module>
run()
File "/projects/build/build/virtualenv/prod/lib/python3.4/site-packages/deco/conc.py", line 54, in __call__
return self.f(*args, **kwargs)
File "<string>", line 4, in run
File "/projects/build/build/virtualenv/prod/lib/python3.4/site-packages/deco/conc.py", line 108, in __call__
self.replaceWithProxies(kwargs)
File "/projects/build/build/virtualenv/prod/lib/python3.4/site-packages/deco/conc.py", line 86, in replaceWithProxies
args_iter = args.iteritems() if type(args) is dict else enumerate(args)
AttributeError: 'dict' object has no attribute 'iteritems'
It should be easy enough to not use iteritems.
Is there a plan to make deco compatible with both python2 and python3?
In fact, changing the one use of iteritems to items seems to be all it takes to make deco run in python3
Please please... https://github.com/alex-sherman/deco/issues/new
FYI: I'm having trouble with your first example on Windows 10. https://github.com/alex-sherman/deco/issues/55
Python Threading Vs. Multiprocessing
The threading module uses threads, the multiprocessing module uses processes. The difference is that threads run in the same memory space, while processes have separate memory. This makes it a bit harder to share objects between processes with multiprocessing. Since threads use the same memory, precautions have to be taken or two threads will write to the same memory at the same time. This is what the global interpreter lock is for. Spawning processes is a bit slower than spawning threads. Once they are running, there is not much difference.
http://net-informations.com/python/iq/multi.htm