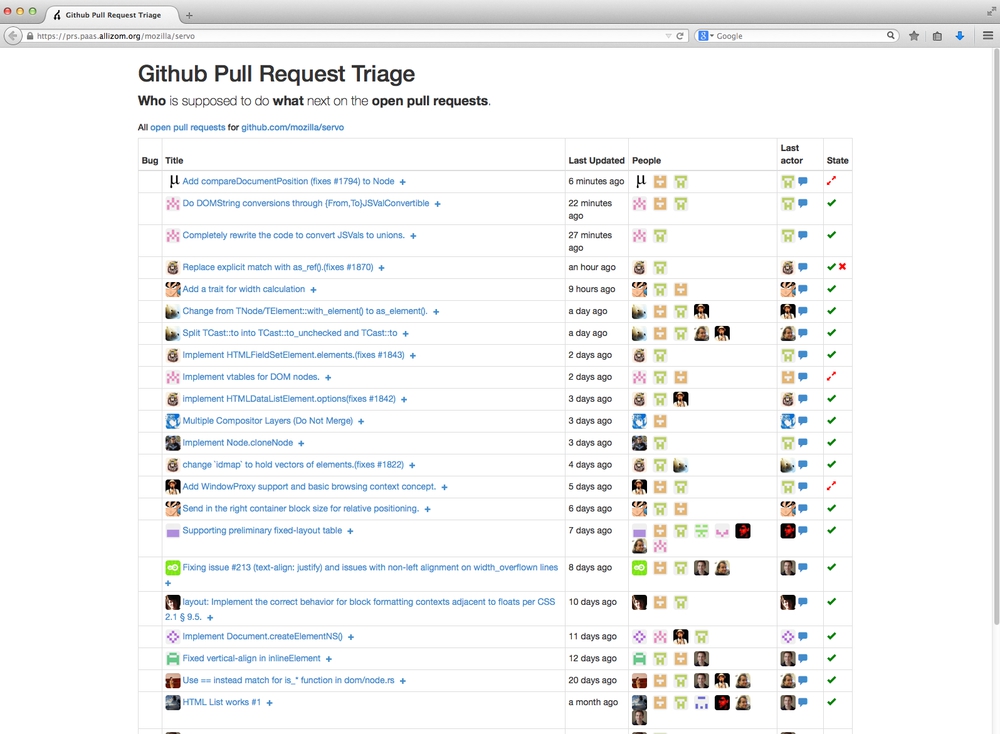
Last week I built a little tools called github-pr-triage. It's a single page app that sits on top of the wonderful GitHub API v3.
Its goal is to try to get an overview of what needs to happen next to open pull requests. Or rather, what needs to happen next to get it closed. Or rather, who needs to act next to get it closed.
It's very common, at least in my team, that someone puts up a pull request, asks someone to review it and then walks away from it. She then doesn't notice that perhaps the integrated test runner fails on it and the reviewer is thinking to herself "I'll review the code once the tests don't fail" and all of a sudden the ball is not in anybody's court. Or someone makes a comment on a pull request that the author of the pull requests misses in her firehose of email notifictions. Now she doesn't know that the comment means that the ball is back in her court.
Ultimately, the responsibility lies with the author of the pull request to pester and nag till it gets landed or closed but oftentimes the ball is in someone elses court and hopefully this tool makes that clearer.
Here's an example instance: https://prs.paas.allizom.org/mozilla/socorro
Currently you can use prs.paas.allizom.org for any public Github repo but if too many projects eat up all the API rate limits we have I might need to narrow it down to use mozilla repos. Or, you can simply host your own. It's just a simple Flask server
About the technology
I'm getting more and more productive with Angular but I still consider myself a beginner. Saying that also buys me insurance when you laugh at my code.
So it's a single page app that uses HTML5 pushState and an angular $routeProvider to make different URLs.
The server simply acts as a proxy for making queries to api.github.com and bugzilla.mozilla.org/rest and the reason for that is for caching.
Every API request you make through this proxy gets cached for 10 minutes. But here's the clever part. Every time it fetches actual remote data it stores it in two caches. One for 10 minutes and one for 24 hours. And when it stores it for 24 hours it also stores its last ETag so that I can make conditional requests. The advantage of that is you quickly know if the data hasn't changed and more importantly it doesn't count against you in the rate limiter.