When you use a web framework like Tornado, which is single threaded with an event loop (like nodejs familiar with that), and you need persistency (ie. a database) there is one important questions you need to ask yourself:
Is the query fast enough that I don't need to do it asynchronously?
If it's going to be a really fast query (for example, selecting a small recordset by key (which is indexed)) it'll be quicker to just do it in a blocking fashion. It means less CPU work to jump between the events.
However, if the query is going to be potentially slow (like a complex and data intensive report) it's better to execute the query asynchronously, do something else and continue once the database gets back a result. If you don't all other requests to your web server might time out.
Another important question whenever you work with a database is:
Would it be a disaster if you intend to store something that ends up not getting stored on disk?
This question is related to the D in ACID and doesn't have anything specific to do with Tornado. However, the reason you're using Tornado is probably because it's much more performant that more convenient alternatives like Django. So, if performance is so important, is durable writes important too?
Let's cut to the chase... I wanted to see how different databases perform when integrating them in Tornado. But let's not just look at different databases, let's also evaluate different ways of using them; either blocking or non-blocking.
What the benchmark does is:
- On one single Python process...
- For each database engine...
- Create X records of something containing a string, a datetime, a list and a floating point number...
- Edit each of these records which will require a fetch and an update...
- Delete each of these records...
I can vary the number of records ("X") and sum the total wall clock time it takes for each database engine to complete all of these tasks. That way you get an insert, a select, an update and a delete. Realistically, it's likely you'll get a lot more selects than any of the other operations.
And the winner is:
pymongo!! Using the blocking version without doing safe writes.
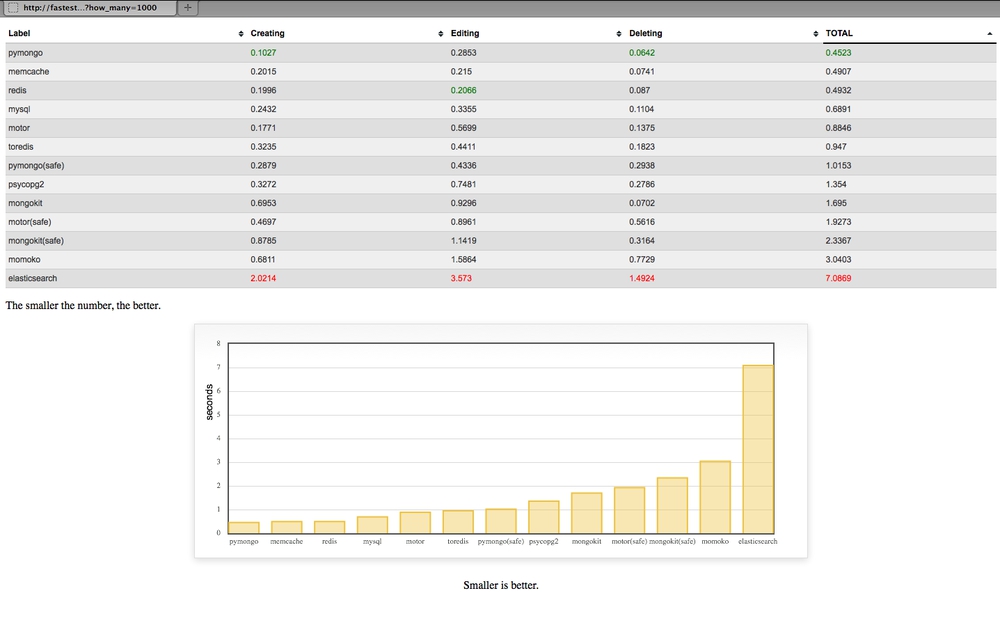
Let me explain some of those engines
- pymongo is the blocking pure python engine
- with the redis, toredis and memcache a document ID is generated with
uuid4, converted to JSON and stored as a key - toredis is a redis wrapper for Tornado
- when it says
(safe)on the engine it means to tell MongoDB to not respond until it has with some confidence written the data - motor is an asynchronous MongoDB driver specifically for Tornado
- MySQL doesn't support arrays (unlike PostgreSQL) so instead the
tagsfield is stored astextand transformed back and fro as JSON - None of these database have been tuned for performance. They're all fresh out-of-the-box installs on OSX with homebrew
- None of these database have indexes apart from ElasticSearch where all things are indexes
- momoko is an awesome wrapper for psycopg2 which works asyncronously specifically with Tornado
- memcache is not persistant but I wanted to include it as a reference
- All JSON encoding and decoding is done using ultrajson which should work to memcache, redis, toredis and mysql's advantage.
- mongokit is a thin wrapper on pymongo that makes it feel more like an ORM
- A lot of these can be optimized by doing bulk operations but I don't think that's fair
- I don't yet have a way of measuring memory usage for each driver+engine but that's not really what this blog post is about
- I'd love to do more work on running these benchmarks on concurrent hits to the server. However, with blocking drivers what would happen is that each request (other than the first one) would have to sit there and wait so the user experience would be poor but it wouldn't be any faster in total time.
- I use the official elasticsearch driver but am curious to also add Tornado-es some day which will do asynchronous HTTP calls over to ES.
You can run the benchmark yourself
The code is here on github. The following steps should work:
$ virtualenv fastestdb $ source fastestdb/bin/activate $ git clone https://github.com/peterbe/fastestdb.git $ cd fastestdb $ pip install -r requirements.txt $ python tornado_app.py
Then fire up http://localhost:8000/benchmark?how_many=10 and see if you can get it running.
Note: You might need to mess around with some of the hardcoded connection details in the file tornado_app.py.
Discussion
Before the lynch mob of HackerNews kill me for saying something positive about MongoDB; I'm perfectly aware of the discussions about large datasets and the complexities of managing them. Any flametroll comments about "web scale" will be deleted.
I think MongoDB does a really good job here. It's faster than Redis and Memcache but unlike those key-value stores, with MongoDB you can, if you need to, do actual queries (e.g. select all talks where the duration is greater than 0.5). MongoDB does its serialization between python and the database using a binary wrapper called BSON but mind you, the Redis and Memcache drivers also go to use a binary JSON encoding/decoder.
The conclusion is; be aware what you want to do with your data and what and where performance versus durability matters.
What's next
Some of those drivers will work on PyPy which I'm looking forward to testing. It should work with cffi like psycopg2cffi for example for PostgreSQL.
Also, an asynchronous version of elasticsearch should be interesting.
UPDATE 1
Today I installed RethinkDB 2.0 and included it in the test.
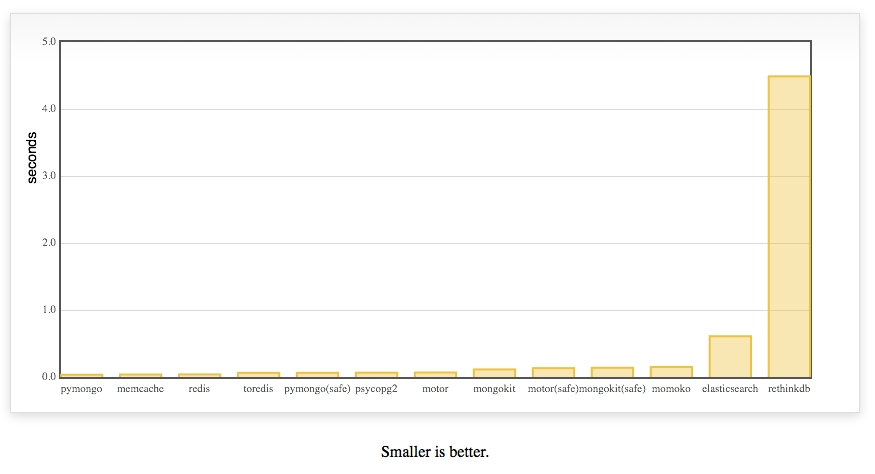
It was added in this commit and improved in this one.
I've been talking to the core team at RethinkDB to try to fix this.
Comments
Post your own commentToo bad it does not have much support as Django
Support?
Nice post!
But I think it would be nice if you do it with a Vagrant, this way the hole benchmark is kept (including the machine).
Hi Peter,
My name is Bernardo Heynemann and I'm the creator and (currently) only committer on MotorEngine.
I did some benchmarks (although anecdotal) on Motor, PyMongo, MongoEngine and MotorEngine.
What I found out is that when performing database operations, pyMongo and MongoEngine are WAY faster than Motor and MotorEngine (which I kind of expected, due to the way tornado asyncs stuff enqueueing it in the ioloop).
That said, when using Tornado under some stress, they all yielded the same number of requests per second (roughly), which I concluded means not blocking actually pays off.
I haven't pursued this more because MotorEngine is still very much work in progress. Once it's more stable I'll try to get a much more comprehensive benchmark suite. I still believe that even if the requests are SLOWER (which they will be) it does pay off releasing the IoLoop to make sure you get to accept the next request.
What do you think?
Cheers,
Bernardo Heynemann
Testing the asynchronous nature is a whole different beast.
I think a decent test would be to write a REST api so that each client can do something like this:
ids = []
for i in range(HOW_MANY_TIMES):
r = request.post('http://localhost:8000/benchmark/create', topic=random_topic(), ...)
assert r.status_code == 200
ids.append(r.content)
for id in ids:
r = request.post('http://localhost:8000/benchmark/edit', id=id, topic=random_topic(), ...
assert r.status_code == 200
for id in ids:
r = request.post('http://localhost:8000/benchmark/delete', id=id, topic=random_topic(), ...
assert r.status_code == 200
Then, you run that concurrently, once for each database engine and count the total time it took to complete everything.
For me this project actually served as a nice first-time tutorial of Tornado.
have you tried using https://github.com/leporo/tornado-redis ?
it seems to be more mature than toredis
Hi Peter,
as mentioned elsewhere, one thing to point out about the new RethinkDB results is that they are using the default setting of "hard" durability from what I can tell.
Hard durability means that every individual write will wait for the data to be written to disk before the next one is run in this benchmark.
As far as I can tell, none of the other databases in this benchmark are configured to wait for disk writes. Depending on your disk and whether it's an SSD or rotational drive, this can easily result in a performance difference of 10x-1000x.
MongoDB's `safe` mode for example would be equivalent to RethinkDB's "soft" durability: Both of them acknowledge a write as soon as it has been applied to the data set in memory. However they don't wait until the data has been persisted to disk (this happens lazily in the background).
For more comparable results, I recommend running with the line `rethinkdb.db('talks').table_create('talks', durability='soft').run(conn)` which is currently commented out in your code.
- Daniel @ RethinkDB
"However, the reason you're using Tornado is probably because it's much more performant that more convenient alternatives like Django". This is (or at least should be) false in the vast majority of the cases, if not all. Please if you want to be fast with Django it has its ways to go (a good way to start is reading the Book: High Performance Django). You use or should use Tornado for real time purposes in the 99,9% of the times, that is long polling, http2, websockets... something cannot be done (at least as good as Tornado or Twisted, although there're ways like gevent, channels...). Of course when you need asynchronous requests/processing or real-time streams you can and probably you should rely in ACID databases, no matter if it's MySQL, Postgresql or Rethinkdb. In the case of Postgresql, there a couple of libraries to wrap psycopg2 properly for tornado.
And before saying "if you have a huge number of requests per second you are not tied to the number of workers or the database I/O capacity" please consider that you are in the 0,01% or less of the cases. For the rest, keep in mind this: "don't use Tornado instead of Django (or WSGI, synchronous stack) because of performance, and even less droping ACID database for the very same reason".