Following on from yesterday's blog about How and why to use django-mongokit I extended the exampleproject which is inside the django-mongokit project with another app called exampleapp_sql which does the same thing as the exampleapp but does it with SQL instead. Then I added a very simple benchmarker app in the same project and wrote three functions:
- One to create 10/100/500/1000 instances of my class
- One to edit one field of all 10/100/500/1000 instances
- One to delete each of the 10/100/500/1000 instances
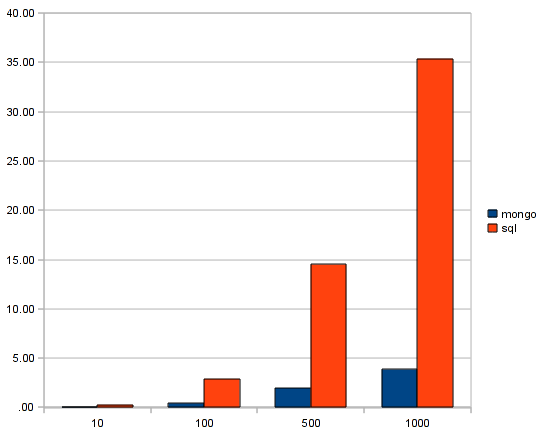
The results can speak for themselves:
# 10
mongokit django_mongokit.mongodb
Creating 10 talks took 0.0108649730682 seconds
Editing 10 talks took 0.0238521099091 seconds
Deleting 10 talks took 0.0241661071777 seconds
IN TOTAL 0.058883190155 seconds
sql django.db.backends.postgresql_psycopg2
Creating 10 talks took 0.0994439125061 seconds
Editing 10 talks took 0.088721036911 seconds
Deleting 10 talks took 0.0888710021973 seconds
IN TOTAL 0.277035951614 seconds
# 100
mongokit django_mongokit.mongodb
Creating 100 talks took 0.114995002747 seconds
Editing 100 talks took 0.181537866592 seconds
Deleting 100 talks took 0.13414812088 seconds
IN TOTAL 0.430680990219 seconds
sql django.db.backends.postgresql_psycopg2
Creating 100 talks took 0.856637954712 seconds
Editing 100 talks took 1.16229200363 seconds
Deleting 100 talks took 0.879518032074 seconds
IN TOTAL 2.89844799042 seconds
# 500
mongokit django_mongokit.mongodb
Creating 500 talks took 0.505300998688 seconds
Editing 500 talks took 0.809900999069 seconds
Deleting 500 talks took 0.65673494339 seconds
IN TOTAL 1.97193694115 seconds
sql django.db.backends.postgresql_psycopg2
Creating 500 talks took 4.4399368763 seconds
Editing 500 talks took 5.72280597687 seconds
Deleting 500 talks took 4.34039878845 seconds
IN TOTAL 14.5031416416 seconds
# 1000
mongokit django_mongokit.mongodb
Creating 1000 talks took 0.957674026489 seconds
Editing 1000 talks took 1.60552191734 seconds
Deleting 1000 talks took 1.28869891167 seconds
IN TOTAL 3.8518948555 seconds
sql django.db.backends.postgresql_psycopg2
Creating 1000 talks took 8.57405209541 seconds
Editing 1000 talks took 14.8357069492 seconds
Deleting 1000 talks took 11.9729249477 seconds
IN TOTAL 35.3826839924 secondsOn average, MongoDB is 7 times faster.
All in all it doesn't really mean that much. We expect MongoDB to be faster than PostgreSQL because what it lacks for in features it makes up for in speed. It's interesting to see it in action and nice to see that MongoKit is fast enough to benefit from the database's speed.
As always with benchmarks: Lies, lies and more damn lies! This doesn't really compare apples for apples but hopefully with django-mongokit the comparison is becoming more fair. Also, you're free to fork the project on github and do your optimizations and re-run the tests yourself.
Comments
Post your own commentCan you compare the timing for making queries?
Single table/document queries, and then joined tables/simulated joins. I wonder how the benefits from I/O surpass the query times, and vice-versa.
I could. Perhaps when time allows. Feel free to fork it on github if you feel like you want to test something that is more relevant to your real-life projects.
What about SELECTs?
Both when it retrieves for editing and for deleting it does selects by key.
I'm following your posts carefully :-)
It seems, that "good old SQL" is often slower in those "create 1000 objects" benchmarks. MySQL has some benchmarks, that make PostgreSQL look like a slow database. SQLite is also very fast, when compared to MySQL. BerkeleyDB may be even faster ;) unfortunatley, some OSS projects I know stopped using it at some point. But well then, again, creating as many objects as possible quickly may be really your app model, so...
How about other benchmarks, like "update every record, that matches 3 - 4 foreign keys AND an IN() range query"?
What about data reliability?
Default PostgreSQL installation is also far from perfect. If speed is your goal, then you can tune PostgreSQL not to use disk that often - disable fsync, set a large COMMIT delay and so on. These settings make the database unreliable in case of power-loss, but for me - I run django tests on local machine - they make testing way faster.
Just my $0.05. For some time in my life, I neglected SQL databases. This didn't turn out to be as good as I thought.
I'm sure there are parameters to make it faster but there are parameters to make MongoDB faster too.
Truth is, when speed matters it's probably because your project matters. And if your project matters your data matters and then you'll need to take reliability and durability to a whole new level and you'd have to start over with the benchmarks.
You're comparing 1000 transactions vs. 1000 inserts to a database that does not guarantee durability.
Try running the tests when you wrap the inserts into *one* transaction.
Lack of transactions is definitely a key pain point. It changes your code as you need to do fewer things per function when you can't rely on rollback to save you.
But do note that the view in the benchmark does not use transactions. So I *am* comparing 1000 inserts vs. 1000 inserts.
> So I *am* comparing 1000 inserts vs. 1000 inserts.
No you dont.
Postgresql will add an implicit transactions if no one opened an explicit one.
In your special case you are using django without transactions in your code. Djangos documentation states that per default it will wrap every call in one transaction.
So basically you are dealing with 1000 explicit transactions and 1000 inserts on PGs side.
Sorry to say that but your benchmark results are misleading.
Also note that this is a syntetic micro benchmark. In real world there would be many queries within one transaction and also bulk queries to get rid of the client<>db roundtrip.
Perhaps you're right. Perhaps PostgreSQL is faster than the benchmark makes it out to look. But this is how Django+PostgreSQL works together.
Also, like I said before, both "sides" of this benchmark can be optimized further.
Michael, there are other postgres tuning parameters that help with throughput with concurrent updates without sacrificing durability.
Basically, you tell postgres to wait to see if any other transactions complete within a given time window so it can log them all at once. The cost is some potential latency as some transactions may not return as quickly. Look at commit_delay and commit_siblings. You may also need to tweak wal_buffers.
Good benchmarks peter. I tried to insert django Mysql model with 24018 entries into mongoDB. It took 2.037 secs to get all entries from Mysql (InnoDB all indexes well fit into RAM) and 17.xx seconds to insert all 24K entries. Its pretty fast.
Fast indeed. But 24k objects isn't really a lot. What would be interesting is to know the speed when there are already 24m inserted.
I hear that Tokyo Cabinet is fast to write but dog slow to *index* when the total number goes up.
I wonder how fast MongoDB would be to insert 24k entries where you already have 1m, 10m or 100m entries in there already.
You can compare mongo to PostgreSQL whole query pipeline (in PG sql parser, query optimizer and runner), but consider comparing only PG datastore with mongo:
1. user PREPARE .. EXECUTE in PostgreSQL to skip part of sql parser and all of optimizer part:
PREPARE query AS INSERT INTO table (id, name, value) VALUES ($1, $2, $3);
EXECUTE query('11', 'new', 'item');
2. Use Copy. This will show true PG performance by inserting CSV values into database table.
COPY FROM '/var/tmp/file.csv' INTO table;
MongoDB is fast
150mb not in use
read data from memory and output on list?