This is an advanced topic for people who do serious stuff in Redis. I need to do serious stuff in Redis so I'm trying to learn about the best way to store lots of keys with hash maps.
It seems that this article by Salvatore Sanfilippo (creator of Redis) himself seems to be a much cited article for this topic. If you haven't read it, the gist is that Redis can employ some clever optimizations for storing hash maps in a very memory efficient way instead of storing each key-value separately.
"Hashes, Lists, Sets composed of just integers, and Sorted Sets, when smaller than a given number of elements, and up to a maximum element size, are encoded in a very memory efficient way that uses up to 10 times less memory (with 5 time less memory used being the average saving)"
This efficient storage optimization is called a ziplist.
How does that work?
Suppose you have 1,000 keys (with their values) if you store them like this:
SET keyprefix0001 valueX SET keyprefix0002 valueY SET keyprefix0003 valueN ... INFO
then, the total memory footprint of the Redis DB is linear. The total memory footprint is roughly that of the length of the keys and values.
Alternatively, if you use hash maps (essentially storing dictionaries instead of individual values) you can benefit from some of those "tricks". To do that, you need to "bucketize" or "shard" the keys. Basically, some way to lump together many keys under one "parent key". (Note this is only applicable if you have huge number of keys)
In this article for one of the founders of Instagram, Mike Krieger, proposes a technique of dividing his keys (since they're all numbers) by 1000 and use the "remainder" as the key inside the hash map. So an original key like "1155315"'s prefix becomes "1155" (1155315 / 1000 = 1155) so he stores:
HSET "1155" "1155315" THEVALUE
Since the numbers are all integers the first 4 characters means there are 10,000 different combinations. I.e. a total 10,000 hash maps.
So when you need to look up the value of key "1155315" you apply the same logic you did when you inserted it.
HGET "1155" "1155315"
So this is where hash-max-ziplist-entries comes in. It's a configuration setting. In my Redis 3.2 install (both in an official Redis Docker image and on my Homebrew install) this number is 512. So what does that mean?
I believe, it means the maximum number of keys per hash map to benefit from the internal space optimization storage.
Real experiment
To demonstrate my understanding to myself, I wrote a hacky script that stores 1,000,000 keys with different "bucketization algorithms" (yeah, I made that term up). Depending how you run the script, it splits the keys (which are all integers) into different number of buckets. For example, if you integer divide each key by 500 you get 2,000 different hash map buckets, aka. total number of keys in the database.
So I run that script with a bunch of different sizes, flush the database between each run and at the end of every run I log how big the whole database is in number of megabytes. Draw a graph of this and this is what you get:
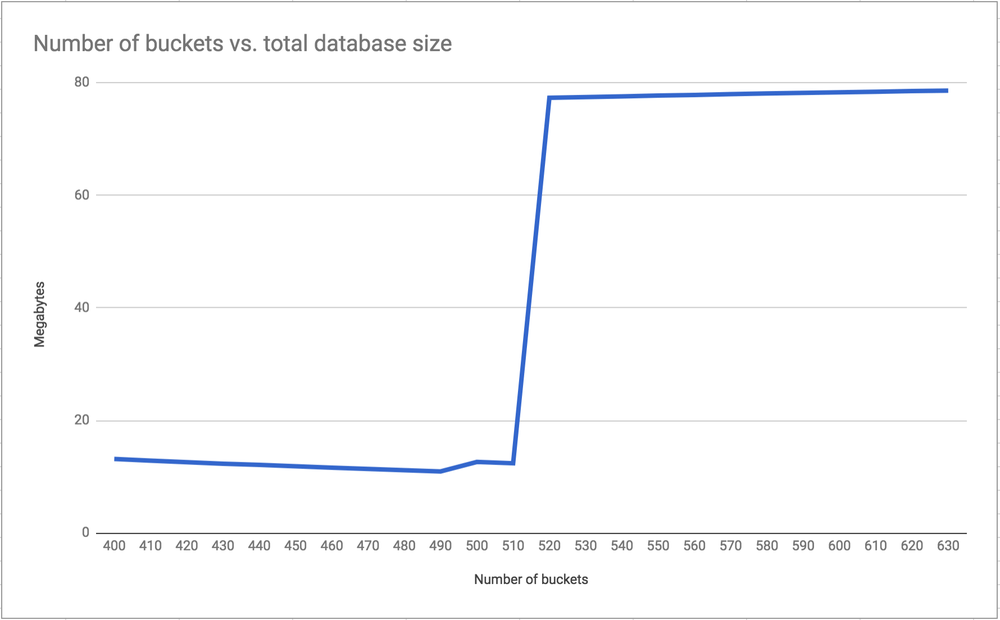
What's happening here is that since my hash-max-ziplist-entries is 512, around there, Redis does not want to store each hash map in space efficient way and stores it has plain key values.
In other words, when each hash map has more than 502 keys, memory usage shoots up.
Sanity check
It's no surprise that the more keys (and values) you store, the bigger the total size of the database. Here's a graph I used when inserting 10,000 integer keys, 20,000 integer keys etc.
The three lines represent 3 different batches of experiments. SET means it inserts N keys with the simple SET operator. HSET (1,000) inserts N keys with each key bucket is 1,000 keys. And lastly, HSET (500) means each hash map bucket has at most 500 keys.
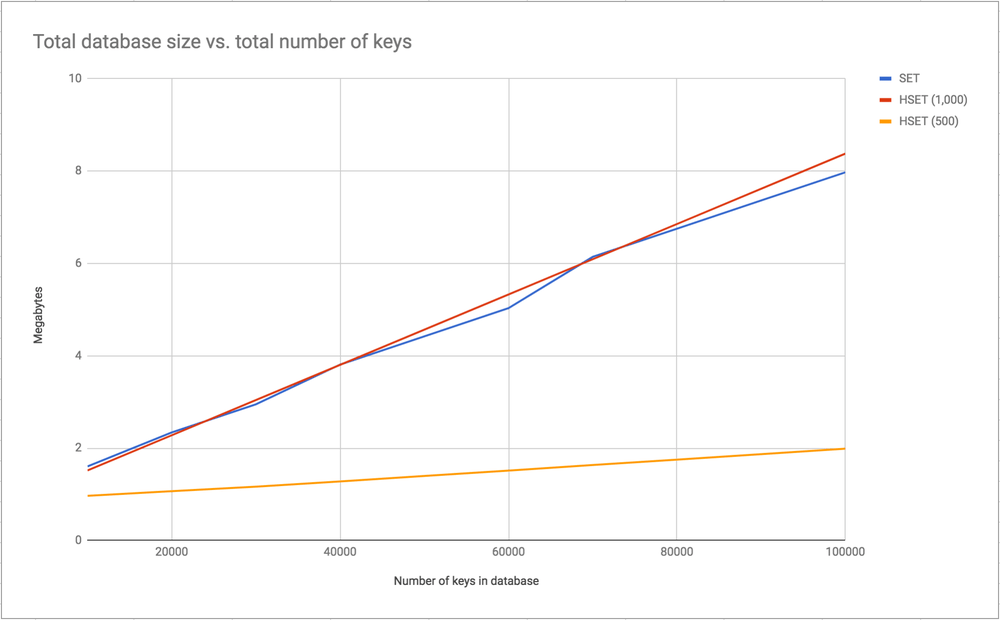
I guess you could say they're all linear but note that they all store the exact same total amount of information.
What's the catch?
I honestly don't know but one thing is clear; there's no such thing as a free lunch.
In the memory-optimization article by Salvatore he alludes that "... a clear tradeoff between many things: CPU, memory, max element size.". So perhaps this neat trick that saves so much memory can comes at a cost of more CPU resource work. At the moment I don't know of a good way to measure this. So far my focus has been on the optimal way of storing things.
Also, I can only speculate but common sense smells like if that number (hash-max-ziplist-entries) is very large, Redis might allocate more memory for the tree it might store than it actually stores. Meaning if I set it to, say, 10,000 but most of my hash maps only have around 1,000 keys. Does that mean that the total memory usage goes up with empty memory allocations?
What to do
Why it's set to 512 by default in Redis 3.2 I don't know, but I know you can change it!
redis-store:6379> config get hash-* 1) "hash-max-ziplist-entries" 2) "512" 3) "hash-max-ziplist-value" 4) "64" redis-store:6379> config set hash-max-ziplist-entries 1024 OK
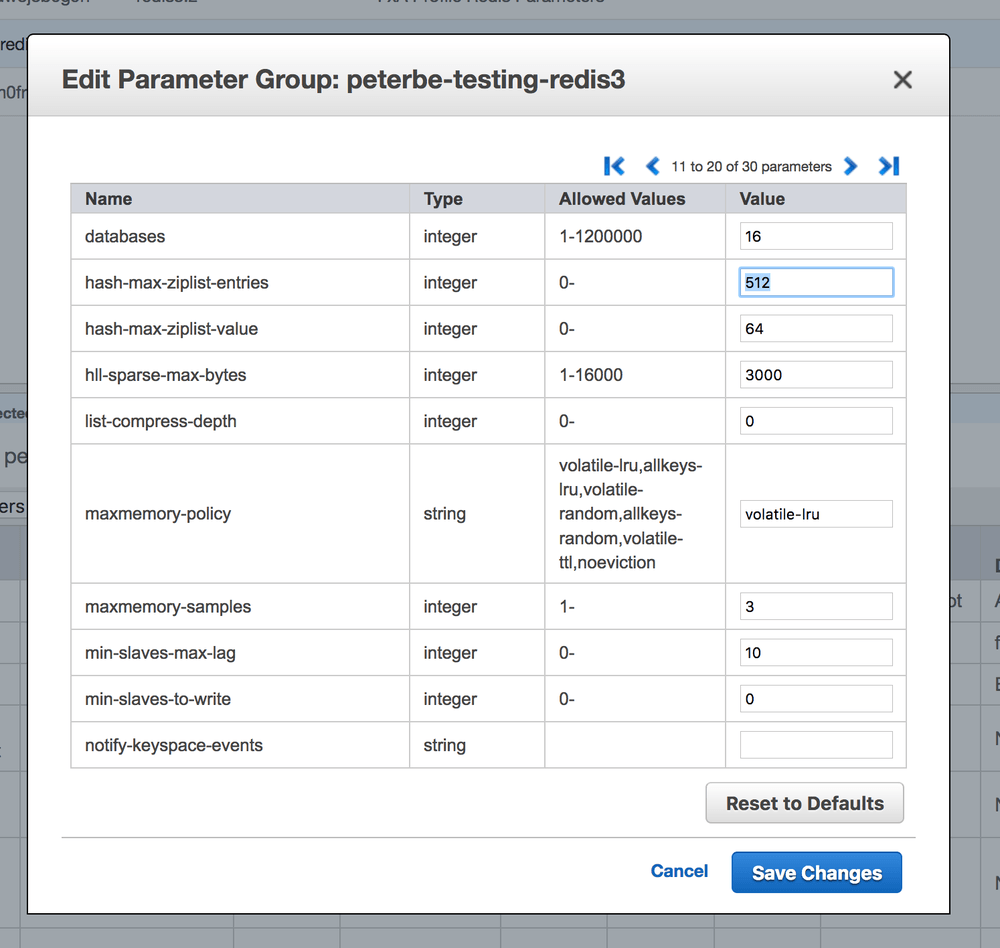
When I make that change and run the original script again but using 1,000 keys per bucket, the whole thing only uses 12MB. So it works.
I haven't actually tested this in AWS ElastiCache but I did try creating a new ElastiCache Parameter Group and there's an input for it.
According to this page it seems it's possible to change it with "Azure Redis Cache" too.
Lastly, I wish there was a way to run Redis where it spits out in a log file somewhere whenever your trip certain thresholds.
Comments
All keys are numeric so is it possible to do some optimisation with alpha numeric keys ?
What if my redis has 1000 keys with each hashmap entry count more than 512 and then I change hash-max-listpack-entries value to 1000 so my all previous keys would fall into this case. Now does redis make changes to previous keys or this param will be valid for only incoming new keys?