tl;dr; git clone https://github.com/mdn/content.git && cd content && yarn install && yarn start && open http://localhost:5000/ will get you all of MDN Web Docs running on your laptop.
The MDN Web Docs is built from a git repository: github.com/mdn/content. It contains all you need to get all the content running locally. Including search. Embedded inside that repository is a package.json which helps you start a Yari server. Aka. the preview server. It's a static build of the github.com/mdn/yari project which handles client-side rendering, search, an just-in-time server-side rendering server.
Basics
All you need is the following:
▶ git clone https://github.com/mdn/content.git ▶ cd content ▶ yarn install ▶ yarn start
And now open http://localhost:5000 in your browser.
This will now run in "preview server" mode. It's meant for contributors (and core writers) to use when they're working on a git branch. Because of that, you'll see a "Writer's homepage" at the root URL. And when viewing each document, you get buttons about "flaws" and stuff. Looks like this:
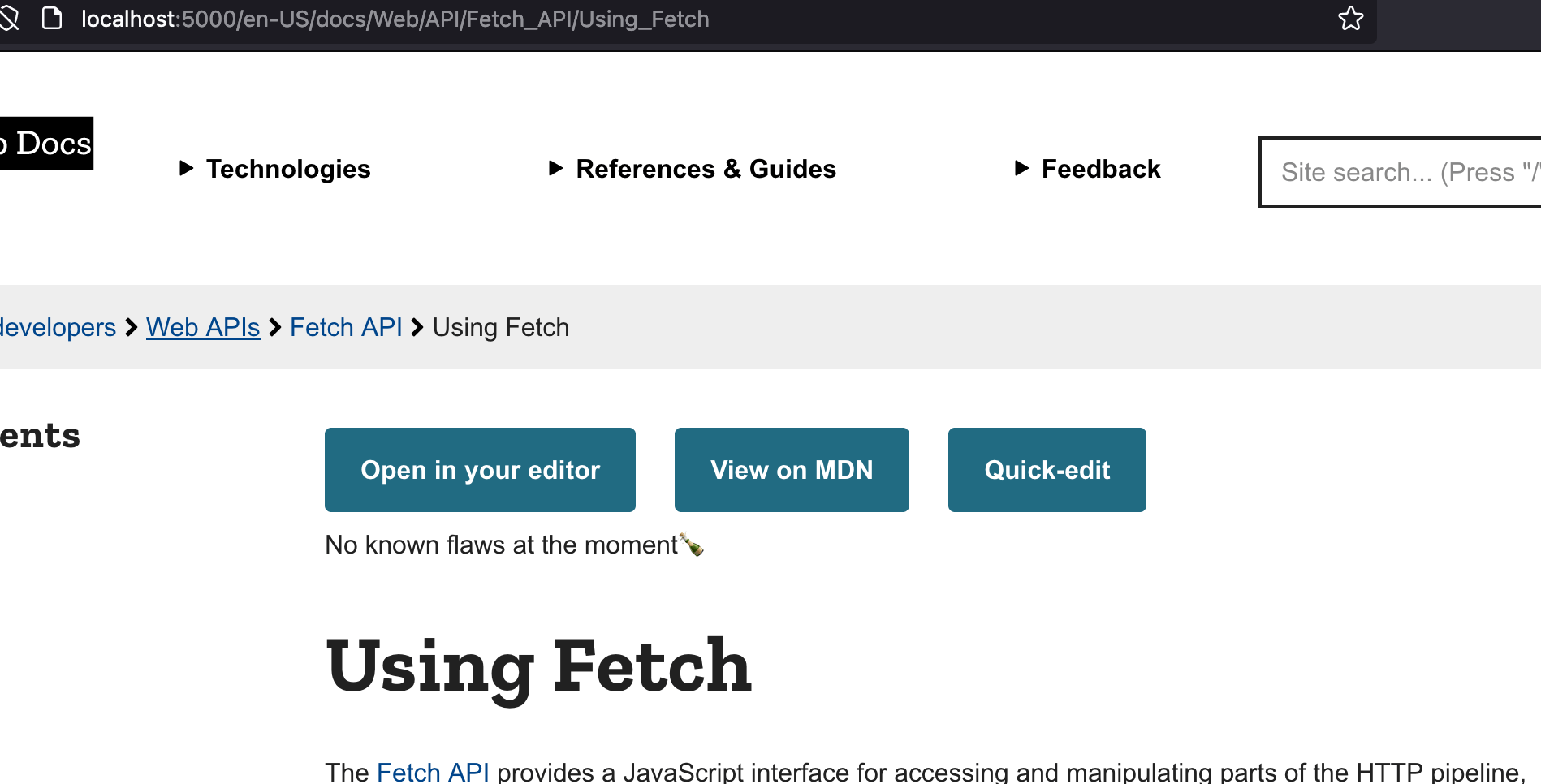
Alternative ways to download
If you don't want to use git clone you can download the ZIP file. For example:
▶ wget https://github.com/mdn/content/archive/refs/heads/main.zip ▶ unzip main.zip ▶ cd content-main ▶ yarn install ▶ yarn start
At the time of writing, the downloaded Zip file is 86MB and unzipped the directory is 278MB on disk.
When you use git clone, by default it will download all the git history. That can actually be useful. This way, when rendering each document, it can figure out from the git logs when each individual document was last modified. For example:
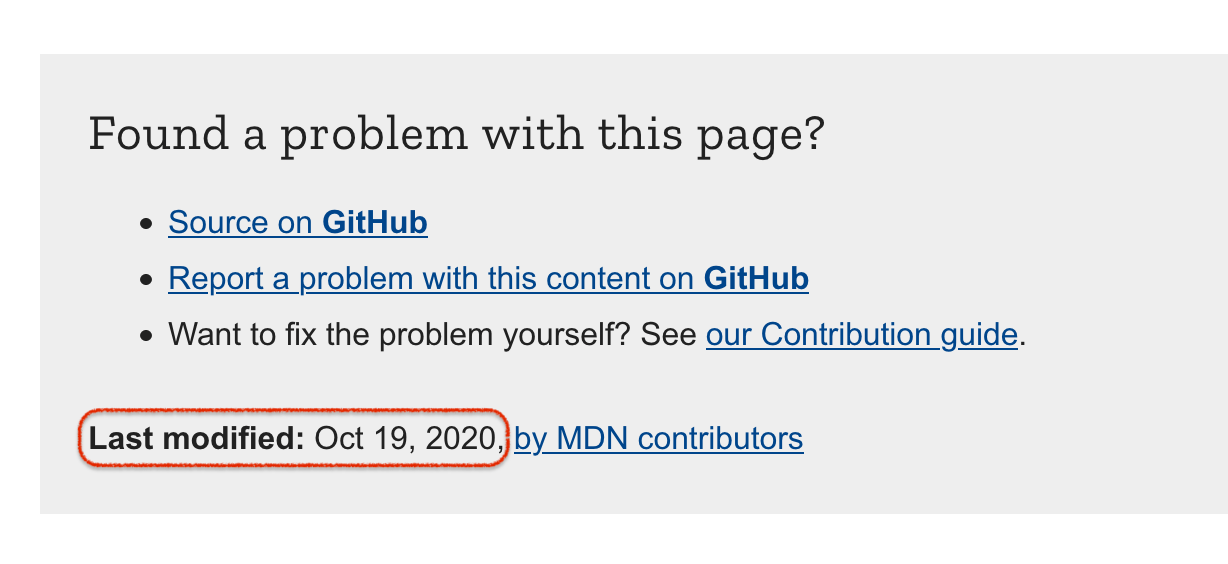
If you don't care about the "Last modified" date, you can do a "shallow git clone" instead. Replace the above-mentioned first command with:
▶ git clone --depth 1 https://github.com/mdn/content.git
At the time of writing the shallow cloned content folder becomes 234MB instead of (the deep clone) 302MB.
Just the raw rendered data
Every MDN Web Docs page has an index.json equivalent. Take any MDN page and add /index.json to the URL. For example /en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/slice/index.json
Essentially, this is the intermediate state that's used for server-side rendering the page. A glorified way of sandwiching the content in a header, a footer, and a sidebar to the side. These URLs work on localhost:5000 too. Try http://localhost:5000/en-US/docs/Web/API/Fetch_API/Using_Fetch/index.json for example.
The content for that index.json is built just in time. It also contains a bunch of extra metadata about "flaws"; a system used to highlight things that should be fixed that is somewhat easy to automate. So, it doesn't contain things like spelling mistakes or code snippets that are actually invalid.
But suppose you want all that raw (rendered) data, without any of the flaw detections, you can run this command:
▶ BUILD_FLAW_LEVELS="*:ignore" yarn build
It'll take a while (because it produces an index.html file too). But now you have all the index.json files for everything in the newly created ./build/ directory. It should have created a lot of files:
▶ find build -name index.json | wc -l 11649
If you just want a subtree of files you could have run it like this instead:
▶ BUILD_FOLDERSEARCH=web/javascript BUILD_FLAW_LEVELS="*:ignore" yarn build
Programmatic API access
The programmatic APIs are all about finding the source files. But you can use the sources to turn that into the built files you might need. Or just to get a list of URLs. To get started, create a file called find-files.js in the root:
const { Document } = require("@mdn/yari/content");
console.log(Document.findAll().count);
Now, run it like this:
▶ export CONTENT_ROOT=files ▶ node find-files.js 11649
Other things you can do with that findAll function:
const { Document } = require("@mdn/yari/content");
const found = Document.findAll({
folderSearch: "web/javascript/reference/statements/f",
});
for (const document of found.iter()) {
console.log(document.url);
}
Or, suppose you want to actually build each of these that you find:
const { Document } = require("@mdn/yari/content");
const { buildDocument } = require("@mdn/yari/build");
const found = Document.findAll({
folderSearch: "web/javascript/reference/statements/f",
});
Promise.all([...found.iter()].map((document) => buildDocument(document))).then(
(built) => {
for (const { doc } of built) {
console.log(doc.title.padEnd(20), doc.popularity);
}
}
);
That'll output something like this:
▶ node find-files.js for 0.0143 for await...of 0.0129 for...in 0.0748 for...of 0.0531 function declaration 0.0088 function* 0.0122
All the HTML content in production-grade mode
In the most basic form, it will start the "preview server" which is tailored towards building just in time and has all those buttons at the top for writers/contributors. If you want the more "production-grade" version, you can't use the copy of @mdn/yari that is "included" in the mdn/content repo. To do this, you need to git clone mdn/yari and install that. Hang on, this is about to get a bit more advanced:
▶ git clone https://github.com/mdn/yari.git ▶ cd yari ▶ yarn install ▶ yarn build:client ▶ yarn build:ssr ▶ CONTENT_ROOT=../files REACT_APP_DISABLE_AUTH=true BUILD_FLAW_LEVELS="*:ignore" yarn build ▶ CONTENT_ROOT=../files node server/static.js
Now, if you go to something like http://localhost:5000/en-US/docs/Web/Guide/ you'll get the same thing as you get on https://developer.mozilla.org but all on your laptop. Should be pretty snappy.
Is it really entirely offline?
No, it leaks a little. For example, there are interactive examples that uses an iframe that's hardcoded to https://interactive-examples.mdn.mozilla.net/.
There are also external images for example. You might get a live sample that refers to sample images on https://mdn.mozillademos.org/files/.... So that'll fail if you're without WiFi in a spaceship.
Conclusion
Making all of MDN Web Docs available offline is, honestly, not a priority. The focus is on A) a secure production build, and B) a good environment for previewing content changes. But all the pieces are there. Search is a little bit tricky, as an example. When you're running it as a preview server you can't do a full-text search on all the content, but you get a useful autocomplete search widget for navigating between different titles. And the full-text search engine is a remote centralized server that you can't take with you offline.
But all the pieces are there. Somehow. It all depends on your use case and what you're willing to "compromise" on.
Comments
Hey I am running into
Errors with dependencies when running yarn and consequently yarn start . Can’t seem to find any help for it elsewhere and your article seems to be the only resource external to the readme of MDN/content GitHub .