tl;dr 36
For some time now, I've been running an experiment where I analyze how many different domains any website depends on. For example, you might have Google Analytics on your site (that's www.google-analytics.com) and you might have a Facebook Like button (that's platform.twitter.com and/or s-static.ak.facebook.com) and you might serve your images from a CDN (that's d1ac1bzf3lrf3c.cloudfront.net). That there is 3-4 distinct domains.
Independent of how many requests come from each domain, I wanted to measure how many distinct domains a website depends on so I wrote a script and started collecting random URLs across the web. Most of the time, to get a sample of different URLs I would take the RSS feed on Digg.com and the RSS feed on Hacker News on a periodic basis.
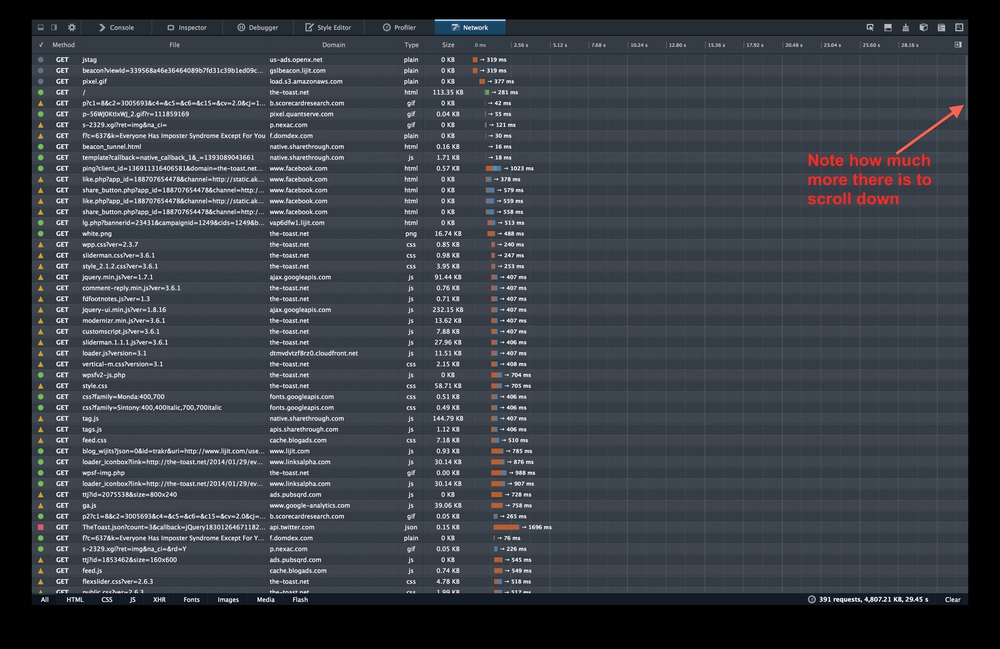
The results are amazing! Some websites depend on over 100 different domain names!
Take this page on The Toast for example, it depends on 143 different domains. Loading it causes your browser to make 391 requests, download 4.8Mb and takes 29 seconds (in total, not necessarily till you can start reading it). What were they thinking!?!
I think what this means is that website makers will probably continue to make websites like this. What we, as web software engineers, can not tell people it's a bad idea but instead to try to do something about it. It's quite far from my expertise but clearly if you want to make the Internet faster, DNS would be an area to focus on.
Test it out for yourself here: Number of Domains
Comments
Post your own commentAlthough i have had a similar idea to solve this, but i think segment.io already solves this nicely. You will literally only add one more domain for any other services API calls. They are however ( in my view ) quite pricey.
I didn't know about segment.io but it seems only to solve the problem with analytics trackers. There's still a zillion other 3rd party things like static asset CDNs.
"The ultimate analytics platform. Send your data to any service with the flick of a switch." Whow thats sounds like a really really horrible idea!! Lets do it! :D .. not!
@Peter: Whow thats a realy cool service with the nodomains page!!! Thanks a lot!
Would it be possible to add the amount of data fetched too?
I think there should be an official quality meter for stuff like that. Maybe like http://validator.w3.org but also with ratings of how much data, use of trackers and or course Nr of domains fetched.
Did you notice any significant difference between HTTP and HTTPS sites?
Huge difference. Average 9 for HTTPS but I think it's possibly skewed because HTTPS sites are usually very functional things where you're there to do work whereas news sites are there to "hook you in" with their desire to get you to Like, Re-tweet, etc.
Neat idea. I noticed that the counts were low for a number of pages, which appears to be due to deferred loading logic. https://gist.github.com/9191642 is a refactored version which uses setInterval to see if all pending requests have completed and waits at least 200ms after that time to allow JavaScript to issue new requests after the first round of load events has fired.
I'll try your script.
Another thing I can imagine is sites that hang on to a onScroll event and load more crap when you've scrolled down a bit.
This is definitely a tedious exercise in detecting the weird things developers try. I wonder how many pages would change if we simply triggered a scroll event after window.load -
I just updated https://gist.github.com/9191642 with longer timeouts and something which triggers scrolling a couple of times, which basically doubles the number of requests and domains for http://www.washingtonpost.com.
But I'm not sure doing a scroll in the script is fair on the site. It's kinda like going to the URL then clicking on another page. Except of a click it's a scroll.
This was quite interesting and seems to confirm my observation that web pages, especially media pages, just keep adding more stuff. (Wired.com is starting to drive me absolutely nuts.) Anyway, I happened to have 82,465 archived web pages available for my research on archive temporal coherence, so I ran some quick numbers: http://ws-dl.blogspot.com/2014/03/2014-03-01-domains-per-page-over-time.html. Thanks for the inspiration!