A project I started before Christmas (i.e. about a month ago) is now production ready.
mincss (code on github) is a tool that when given a URL (or multiple URLs) downloads that page and all its CSS and compares each and every selector in the CSS and finds out which ones aren't used. The outcome is a copy of the original CSS but with the selectors not found in the document(s) removed. It goes something like this:
>>> from mincss.processor import Processor
>>> p = Processor()
>>> p.process_url('https://www.peterbe.com')
>>> p.process()
>>> p.inlines
[]
>>> p.links
[<mincss.processor.LinkResult object at 0x10a3bbe50>, <mincss.processor.LinkResult object at 0x10a4d4e90>]
>>> one = p.links[0]
>>> one.href
'//d1ac1bzf3lrf3c.cloudfront.net/static/CACHE/css/c98c3dfc8525.css'
>>> len(one.before)
83108
>>> len(one.after)
10062
>>> one.after[:70]
u'header {display:block}html{font-size:100%;-webkit-text-size-adjust:100'
To whet your appetite, running it on any one of my pages here on my blog it goes from: 82Kb down to 7Kb. Before you say anything; yes I know its because I using a massive (uncustomized) Twitter Bootstrap file that contains all sorts of useful CSS that I'm not using more than 10% of. And yes, those 10% on one page might be different from the 10% on another page and between them it's something like 15%. Add a third page and it's 20% etc. But, because I'm just doing one page at a time, I can be certain it will be enough.
One way of using mincss is to run it on the command line and look at the ouput, then audit it and give yourself an idea of selectors that aren't used. A safer way is to just do one page at a time. It's safer.
The way it works is that it parses the CSS payload (from inline blocks or link tags) with a relatively advanced regular expression and then loops over each selector one at a time and runs it with cssselect (which uses lxml) to see if the selector is used anywhere. If the selector isn't used the selector is removed.
I know I'm not explaining it well so I put together a little example implementation which you can download and run locally just to see how it works.
Now, regarding Javascript and DOM manipulations and stuff; there's not a lot you can do about that. If you know exactly what your Javascript does, for example, creating a div with class loggedin-footer you can prepare your CSS to tell mincss to leave it alone by adding /* no mincss */ somewhere in the block. Again, look at the example implementation for how this can work.
An alternative is to instead of using urllib.urlopen() you could use a headless browser like PhantomJS which will run it with some Javascript rendering but you'll never cover all bases. For example, your page might have something like this:
$(function() {
$.getJSON('/is-logged-in', function(res) {
if (res.logged_in) {
$('<div class="loggedin-footer">').appendTo($('#footer'));
}
});
});
But let's not focus on what it can not do.
I think this can be a great tool for all of us who either just download a bloated CSS framework or you have a legacy CSS that hasn't been updated as new HTML is added and removed.
The code is Open Source (of course) and patiently awaiting your pull requests. There's almost full test coverage and there's still work to be done to improve the code such as finding more bugs and optimizing.
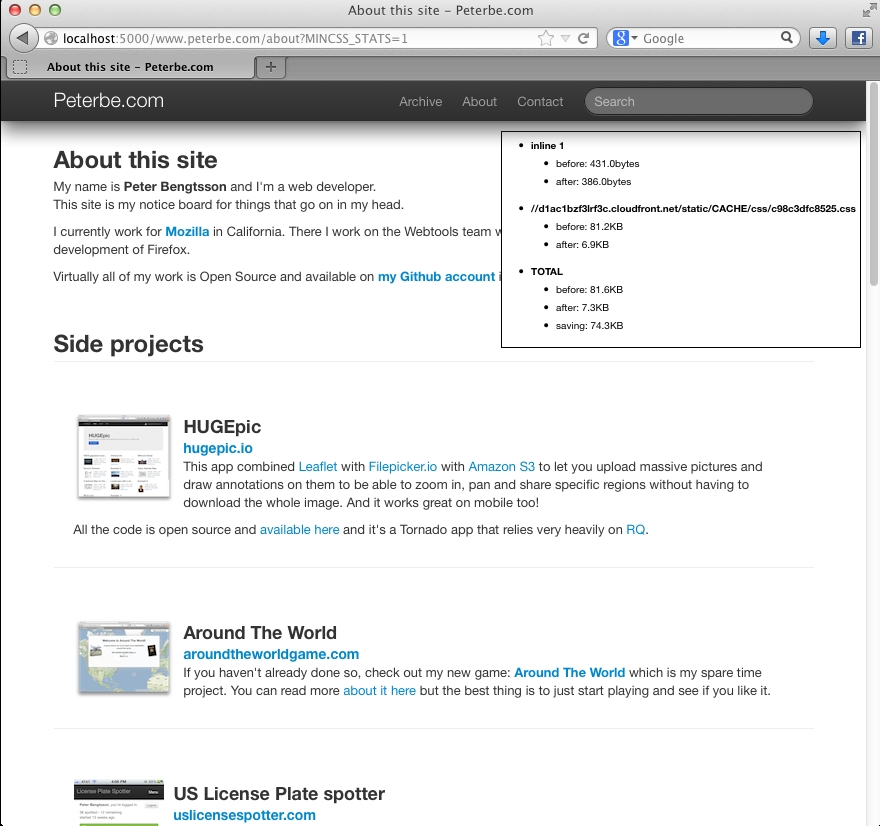
Also, there's a rough proxy server you can start that attempts to run it on any URL. You start it like this:
pip install Flask cd mincss/proxy python app.py
and then you just visit something like http://localhost:5000/www.peterbe.com/about and you can see it in action. That script needs some love since it's using lxml to render the processed output which does weird things to some DOM elements.
I hope it's of use to you.
UPDATE
Published a blog post about using mincss in action
UPDATE 2
cssmin now supports downloading using PhantomJS which means that Javascript rendering will work. See this announcement
UPDATE 3
Version 0.8 is 500% faster now for large documents. Make sure you upgrade!
Comments
Post your own commentLooks very nice, thank you for your work !
FYI: "[...] to wet your appetite [...]". The correct word there is "whet" which means to sharpen or to stimulate.
Thank you! I knew there was something wrong. And the spellchecker wouldn't have found it.
Just have a doubt... How will the program work if in my javascript code i assign a class to a div element which has not been assigned to it in html. like minimize and maximize links in pages. i will toggle between "minimize" and "maximize" classes in js code. minicss will look for css selectors in js files for a match?
RTFA
It doesn't support that. Sorry.
But if you only have a little bit of Javascript like that you can specifically set which selectors are only used by Javascript. See https://github.com/peterbe/mincss/tree/master/example
Thanks for the info. Great useful stuff this. Will use this in my projects.
prdsh, it says it won't take care of that above, you just have to take care and not remove anything that mincss tells you to that you know you are using in your js.
Why would you do this when you can cache your CSS once, and reuse as necessary across your entire site? Now with this, you have to cache the CSS for every page, or worse, overwrite previously cached files because they use the same filename but have different content.
You're solving a problem that doesn't exist, and ironically, by attempting to optimize, you are unoptimizing because you can't see the bigger picture.
It's not as simple as that.
When people visit my site they generally just check out the one page they landed on and then move on to some other site. Actually, Google Analytics tells me my visitors are only visiting 1.17 pages. That means that they get very little benefit to caching the CSS file. Only a fraction of people will benefit.
The benefit however of moving the CSS into the HTML document is that the page loads faster for that one initial load. The "first time impression" will be great!
So, it depends on the nature of your website. Is it an app? Is it a blog? Is it something in between.
And note that people's browsers have limited amount of cache space (especially on mobile devices) so if your visitors only come once a month, many times they return but their browser has forgotten the cached CSS.
And if your visitors refresh the page the external resources are reloaded anyway.
Look all over the web for a CSS cleaner
Will this be something i can install on windows os?
Yes, it should work on Windows. If you can install lxml on Windows you should be ok.
I like this.
The proxy app works better for me if I change the call to etree.tostring to:
etree.tostring(page, pretty_print=True, method='html')
Which *seems* to stop it from truncating tags so the CLOSING_REGEX replacement isn't required.
Good point! I'll add that.
Done now. Not going to make a new release for just that.
Would really be helpful if someone could do a video tutorial
You mean about how to use it?
I doubt I'll get around to that, but tell me, what can we do to improve the documentation to show you how to use it?
Really Great Job , Thank you
Hi Peter,
I'm just returning to this after first seeing it earlier this year year. It looked promising then, and you seem to be getting good feedback. Your points about first impressions and mobile are absolutely right.
I mentioned this on 2013-03-02 to @jezdez, jezdez a@t enn.io, the creator of the django compressor we are using for our bloated css stuff. He agreed that this might well fit with what he is doing. If he has not been in touch with you, perhaps you could consider talking about bundling it.
Best,
--r
Will do.
But I don't see how that bundling would work. After all, it's not until the page is loaded that you can know what was never needed.
Good point, but in django you can easily generate a list of urls, and iterate them.
For parameterised urls one can provide sample stubs to create a valid example page.
Iterate the whole site; calculate the page-by-page essentials; then provide the usual choices about where to put the computed output.
hi, I got the following error for one of my page (while the others are okay)
--
Antons-MacBook-Air:mincss-master antonrifcosusilo$ python run.py -v http://localhost/dev-homepage/v/user_iti --outputdir output_publiciti
TROUBLEMAKER
u'a[href^="javascript'
Traceback (most recent call last):
File "run.py", line 75, in <module>
sys.exit(run(args))
File "run.py", line 19, in run
p.process(args.url)
File "mincss/processor.py", line 122, in process
processed = self._process_content(content, self._bodies)
File "mincss/processor.py", line 308, in _process_content
inner, whole = self._get_contents(m, content)
File "mincss/processor.py", line 396, in _get_contents
c = original_content[position]
IndexError: string index out of range
---
What might be the cause?
thanks
I try to install and see this error:
> python setup.py install
Traceback (most recent call last):
File "setup.py", line 36, in <module>
version=find_version('mincss/__init__.py'),
File "setup.py", line 23, in find_version
version_file, re.M)
File "C:\Python33\lib\re.py", line 161, in search
return _compile(pattern, flags).search(string)
TypeError: can't use a string pattern on a bytes-like object
I don't think mincss works with python3. I've never done any work on porting it.
If you don't require py3 I recommend you install python 2.7.
What about merging with cssmin?
That's up to you. It's really easy.
I have the Python error "ValueError: too many values to unpack". Any idea ? Thanks.
What did you try to do? I'm sure we can figure it out.
I tried the example from github, it worked. Simply $ mincss http://localhost/example/page.html. And when I tried with my heavy-junk-webpage-with tons-of-html I have this error message from Python.
If you have a URL it doesn't work for, add an issue here: https://github.com/peterbe/mincss/issues/new