Common names amongst my Facebook friends
June 26, 2014
1 comment Wondering
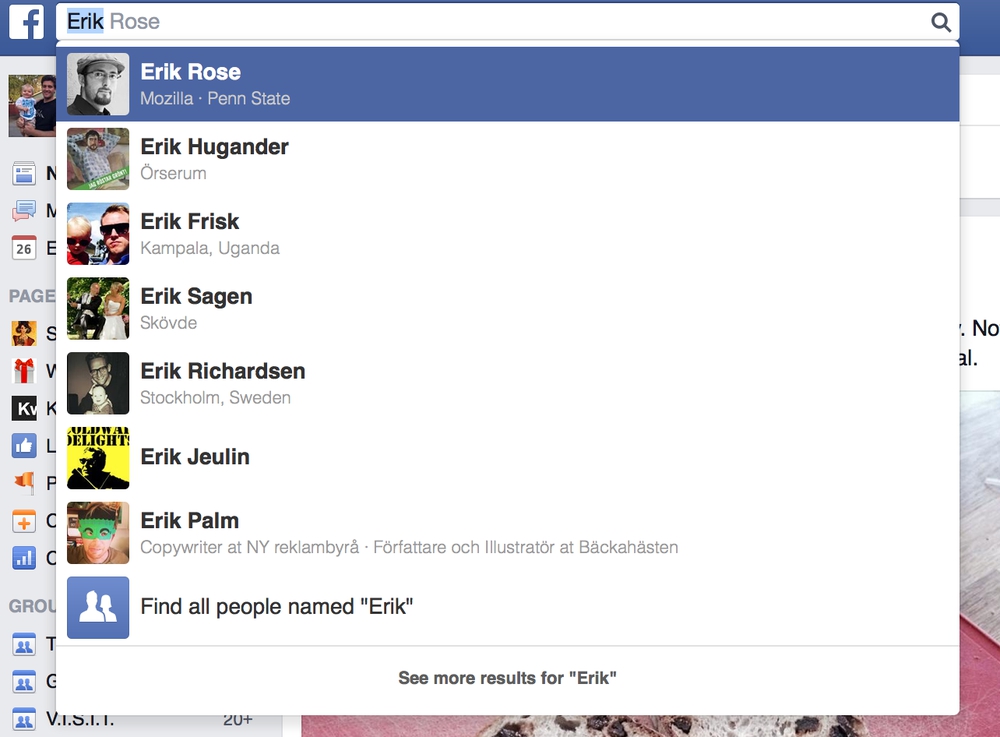
Sometimes it feels like there's almost no unique names amongst my Facebook friends. Whenever I use the search function and start typing someones name at least two friends' names pop up.
However, I only have one friend called Åsa and one friend called Conrad. So it got me wondering how many of my friends names are unique?
So I pulled down the names of all my 500+ friends and counted them. The results were suprising!
| 0 in common | 291 |
| 1 in common | 53 |
| 2 in common | 15 |
| 3 in common | 10 |
| 4 in common | 1 |
| 5 in common | 3 |
| 6 in common | 2 |
That means that 56% of my friends' names are unique! Much more than I expected. I should add, the bulk of my friends are primarily from two countries: USA and Sweden. From all over the world too but these are the most common. However, because of this I have some friends who have the locale's spelling. I.e. "Michael" in USA versus "Mikael" in Sweden.
So, if I manually go through the list and look at some names and come up with some aliases so that Eric and Erik counts as the same name, I get a lot less uniqueness. The list I made is available here and it's very much a quick judgement call based on a rough idea of the "stemming" of these names.
It actually didn't help that much. The spread now looks like this:
| 0 in common | 260 |
| 1 in common | 44 |
| 2 in common | 14 |
| 3 in common | 12 |
| 4 in common | 6 |
| 5 in common | 2 |
| 6 in common | 1 |
| 7 in common | 4 |
And the number of people with unique names goes down to 50.1%. Still more than half.
Last but not least, the most common names for me were:
- Michael (8 people)
- Mat (8)
- Eric (8)
- Christopher (8)
- Dave (7)
- Sara (6)
Free business idea: An app for figuring out the best car for you
January 18, 2013
0 comments Wondering
Here's a business idea that I've not seen implemented and which I likely won't have time to attempt:
An app for statistically figuring out which car you should buy.
Like Hot or Not it shows you one car at a time (at random) with a variable (also at random). The variable will be turned into a question. The question will be something like: "What about the price of this?" and it's a picture of a Toyota Prius 2013 with its price. Three buttons to choose: "Too expensive", "About right", "Too cheap".
Next, it's a different car and a different variable. For example, a Volvo XC90 with the question "What about the looks of this?" and, again, three buttons: "Too ugly", "About right", "Too sexy".

On so on... You can keep going, answering more questions, or you can stop and check out your result. Obviously, the more you answer the better the suggestion. You might want to help the user with this so they don't answer too few.
Then when you present the result you can, on that page, show a bunch of affiliate links to various local dealerships where you can buy the ideal car for you. Additionally, if the app becomes successful I'm sure you can easily sell advertisement to car companies who would love to show their ads depending on certain variables. E.g. Honda Fits for those who answer that they want low MPG and small cars.
The algorithm shouldn't be too hard to figure out. I'm sure you can get a lot of mileage just by doing a weighted average on the totals. If you sit down and think about it some more I'm sure you can fit some better established algorithm or something from the neural networks if you lay out your results as a matrix.
That's about it. I don't know where to get the pictures and specs for each car but I'm sure one can scrape from various sites and/or seed some of it manually.
It's the kind of app where you can start small (assuming you have at least 100 cars and 3-6 facts about each car). Also, it doesn't depend on having a bunch of traffic already so you don't need to worry so much about the chicken & egg predicament.
Do you think it could fly?
Reciprocal lesson about gender perspectives
September 2, 2011
0 comments Wondering
Picked this up on a food blog in one of the comments; a female commenter wrote:
"Guys went for me all the time in my late teens and early twenties. Im no great beauty, but they did anyway. I was slender.
I did not remain slender. No one looks at me now.
I'm the same person."
Err! Wrong! You're not the same person! If we assume that this "slender" versus "not slender" is the differentiating factor and ignore age for now then with beauty changes the person.
It's such a common misconception sometimes heard from women that the personality is one factor of attraction and that external beauty is another. In the opposite, women do play down the external beauty factor more when considering men's total attraction value. Take heed women, your beauty factor matters more than men's. No news there. The mistake here is to think the opposite sex thinks like you do.
So what's the reciprocal lesson in this? For a man. Quite simply: don't think that women think like men. Or in plain English, just because you're a stud, don't think that you can be an ass.
A blog comment spam solution: Retalition!
July 31, 2011
0 comments Wondering
You know all those blog comments that slip through our blog commenting filters. The ones written by humans who pass the captcha tests. The ones who pretend to say something generic but really just want to put a link in to their viagra|laptops|watches|meds selling sites. Yes, those assholes.
What we do is to take their links and stick them on the worlds most spam full website which one of us set up. Access to edit it can be controlled by a ring of trust amongst web developers and tech savvy blog owners. Because being featured on a site like that is going to be noticed by Google as a terrible spam site and therefore flag those URLs as spam thus blocking them from searches and thus ruining it for their owners and thus them giving up on spamming our blogs.
Perhaps someone at Google like Matt Cutts could weigh in and tell us if it's feasible. Perhaps Google already have some tool where individuals can flag individual URLs but that wouldn't have the group-power of something like my idea.
For those familiar with how the Linux Kernal is developed with a distributed source code tool, this could work the same with github patches and layered layers of trust all the way up to Linus Torvalds.
Is it a completely bonkers idea?
ToDo apps I gave up on in 2010
January 3, 2011
4 comments Wondering
First I tried Things for the iPhone which I tried because some people I work with said it was good. It lasted about a week. I think it failed, for me, because I didn't feel how time slowly wipes away old stuff that isn't relevant any more. My todo lists are usually about work projects which mainly means writing code and sending emails to people on the project. Things being on the iPhone meant I had to take my hands off the computer.
The second one I tried is the app with perhaps the most brilliant UI I've seen in years: TeuxDeux There's only three things you can do, enter events and mark them as done. I tried the iPhone version but even though it works well it wasn't as neat as the web version. Eventually I gave up because I think I couldn't keep up with moving past day events forward to today's date. That meant that new events entered "today" sort of got higher priority than old ones and that just felt wrong in the long run.
The third one wasn't really a todo list but that's how I ended up using it: Workflowy Again, an absolutely brilliant UI and technical achievement. I had it as an open tab for about three weeks until I ended up not bothering any more. I love writing bullet point lists to the n'th degree but I felt that every time I came back to it I had to "search" for where I was and had to make a tonne of micro-decisions about where to put stuff. When I had a thought in my head I didn't want to first think and plan where to put it.
What did work?
It's far from applicable to everyone but one thing that has worked (has for many years in fact) was our work issue tracker. We use IssueTrackerProduct, written by yours truely. It's not really fair because when you add the fact that multiple people are using the same tool the personal choices don't really matter. Also, I think project issue trackers like this have the added bonus that you don't clutter them with small basic things like "Check database log X".
The perhaps most successful todo list for me in 2010 was keeping a TODO.txt file in my project source directory. This is a personal file I rarely check in to git because my colleagues don't need to see mine (well, sometimes that's useful too). It's a simple text file and it looks something like this:
* (MEDIUM) render the shared classes in calendar.html on page load
* (HIGH) Find out why all CSS is lost when an event is added
* (LOW) Experiment with http://vis.stanford.edu/protovis/ to write
some nice stats
...I guess it works because it's my own invention. From scratch. Generally todo list apps work best if you wrote the app yourself. It's immediately in context because each code project gets its own file. Its order is implied usually by writing to the top of the file but you can be a bit cowboy about it and just jot things down without doing it "the correct way".
Earl Grey or cheap tea, does it really matter?
March 13, 2007
1 comment Wondering
 All of this week and last week I'm working at a client's office in west London. So I've been away from the sanctuary of our office now for a while. At my usual office I have bought some nice Twinings Earl Grey tea bags. Definitely a favorite of mine.
All of this week and last week I'm working at a client's office in west London. So I've been away from the sanctuary of our office now for a while. At my usual office I have bought some nice Twinings Earl Grey tea bags. Definitely a favorite of mine.
When I started working at this office last week I had to resort to a difference tea that tastes less good. The first couple of cups were all a disappointment but addiction to caffeine probably pulled me back into the kitchen for more cups as the days got on. I drink about 4-5 cups per day and at this stage I don't even remember what good tea tastes like. I actually enjoy this cheap tea just as well.
Because one drinks such vast amounts of tea the taste just becomes what it is and it's only when you change from a quality tea to a cheap tea that you notice the difference. The question is then, as long as you stick to the same tea does it really matter if you drink fancy Earl Grey or cheap industrial tea? Surely the health factor is negligible but the price difference isn't thus going for a cheaper tea would be smarter? And by drinking cheap tea, when you a precious afternoon tea at the Ritz you're going to enjoy the tea even more.
Or should I be stoned and lynched for wasting thinking time on this?